Hi,本周有奖互动话题为「你的模型选择指南是什么」
经常使用 iFlow CLI 的朋友们都知道……
不同模型在开发过程中的不同环节表现各有所长,选模型的关键,不是“谁最强”,而是“谁最合适”![]()
快来留言分享你的模型选择小妙招,给小白们一些灵感~
照例揪 5 位云股东喝星爸爸![]() !
!
感谢大家的热情参与,以下为获奖用户哦:
Hi,本周有奖互动话题为「你的模型选择指南是什么」
经常使用 iFlow CLI 的朋友们都知道……
不同模型在开发过程中的不同环节表现各有所长,选模型的关键,不是“谁最强”,而是“谁最合适”![]()
快来留言分享你的模型选择小妙招,给小白们一些灵感~
照例揪 5 位云股东喝星爸爸![]() !
!
感谢大家的热情参与,以下为获奖用户哦:
我自己使用觉得各个模型的优点:
GLM-前端(React/Vue)、后端服务设计
kimi-长文本(比如说重构旧项目、调用agent)
MiniMax-M2.5-文件整理、文档生成轻量化的操作
Qwen3-Coder-改前端UI的细节
不算骨灰级用户,但是使用的还是比较频繁
个人的选择技巧就是首先看复杂度,像需要从零开发/大规模重构就需要使用高性能模型如 glm-5/kimi-k2.5 之类的模型;如果是普通的代码补全就需要小的模型速度比较快,通常也不涉及复杂逻辑,可以选 qwen3-coder-30b 之类的;如果只是做意图识别之类的简单审查就可以选更小的模型
然后是看任务类型,图片识别就该用视觉模型,向量检索就用 embedding 模型这些就比较常规了
再然后像阅读文档/分析项目的话个人更倾向于使用 minimax-m2.5,虽然代码能力个人觉得一般,但是对 subagent 的调用会更积极,而且速度也快
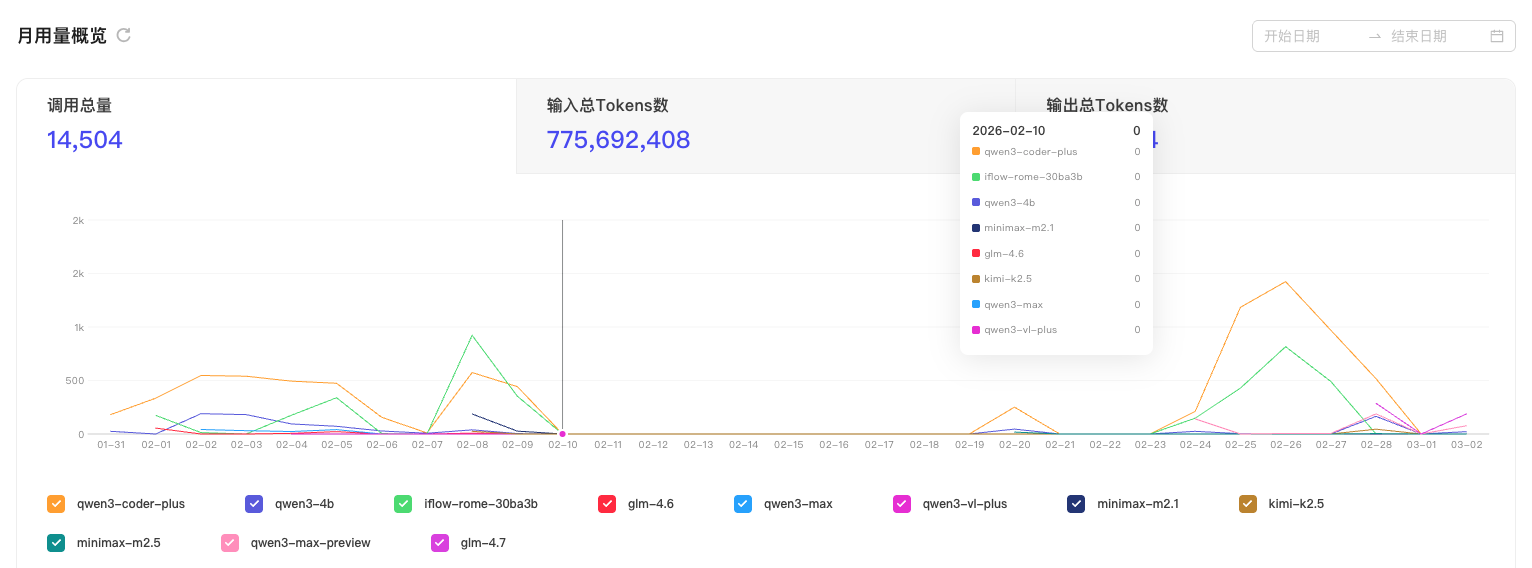
以下是最近正在开发的一个 agent 项目,这是配置模型的截图
在启动 iflow cli 前先安装 spec-kit
iflow workflow add "github-spec-OzctqA"
确保项目目录中出现 .iflow 和 .specify 文件夹
然后启动 iflow cli ,输入以下指令定义项目的基本信息,以下步骤都可以用 minimax-m2.5 进行,属于编写文档,个人认为 minimax-m2.5 比较擅长,而且比较快
/speckit.constitution 我要基于 xxx 开发 xxx 项目,使用 xxx 技术
接着是使用 /speckit.specify 包含 xxx 功能 定义具体功能,可以执行多次,建议一点点定义,不要一口吃成胖子
定义完具体功能,如果不知道是不是还有不清晰的需求可以使用 /speckit.clarify 进行问答式澄清需求
确认需求无误后可以执行 /speckit.plan 制定开发计划,生成计划时还会创建功能分支,让开发历史更清晰,当然发现计划还有问题可以继续执行 /speckit.specify 和 /speckit.clarify
再然后就可以使用 /speckit.tasks 生成任务列表,规划每一步做什么哪些先做哪些后做,哪些可以一起做
完成以上步骤后就切换到代码能力更强的 glm-5 ,如果觉得比较慢可以先用 glm-4.7,然后使用 /speckit.implement 开始正式实施编程计划,不过正式实施之前还可以 /speckit.analyze 来分析任务计划的质量,进一步避免后续 vibe coding 可能出现的隐患等
最后开发完成后可以继续重复 /speckit.specify 起的后续动作,进行继续迭代
glm-5
适合先把需求边界、实现路径、潜在风险讲清楚,前期效率很高,文档方案先梳理好,才能有效产出。
minimax-m2.5
没别的,就是写代码速度快,配合已有方案填坑即可,如果遇到解决不了的问题,会配合使用glm-5。
kimi-k2.5
从 PRD/接口文档提炼开发任务时很好用,调研任务,多工具协调都是很稳的。在加上多模态,有时候我还会让它自己驱动浏览器测试。
glm-4.7
用于交叉验证思路、补测试点、查遗漏,“第二意见”。
我的使用习惯:
一句话总结:
glm-5 定方向,minimax-m2.5 写代码,kimi-k2.5 吃文档,glm-4.7 做复核。
最近在使用kimi2.5 并行Agents初次使用真的被震惊 使用效率明显更快 质量问题暂时还不好说,等待进一步观察;
GLM-4.7 个人使用时间最长的一款,能满足基本日常需求
GLM-5 太消耗资源了,等待时间成倍上涨,token量也不大。个人觉得比较适合从0构建大型项目。
Qwen 3使用经历不太美好,很一般。不建议用作日常开发模型
大多数时候都是用GLM 4.7,用的人少些。稳定性和速度都比较快。在实际使用中,发现GLM 4.7在部分前端任务的表现,不太精确,会出现少导入包,多写括号。
偶尔也用Kimi 2.5和Minimax M2.5,但感觉效果没有GLM 4.7稳定。
平时就三个模型,换着用,GLM 4.7用的多一些。
一般情况下用GLM5,用的人多了我就切k2.5,能力差不多,但速度更快且支持多模态
一定不要上来直接Plan,请先聊天,聊你的需求,聊技术方案。聊完之后再使用Plan
计划使用GLM-5,知识库最新,模型最新,懂得可能也是最多的(个人认为【其实我用的是codex 5.3】![]() )
)
开发计划完毕之后,比较喜欢使用 kimi k2.5开发 【其实我后端用claude sonnet 前端用gemini 3.1 ![]() 】
】
最后使用minimax m2.5跑测试【codex 5.3跑测试 ![]() 】
】
update:
写代码的话国产之前用的比较多的是kimi k2的 0905 版本,还不错
基本就是GLM4.7,主要是遵循指令流程稳定,输出也完成的比较好。
minimax2.5经常不遵循指令流程,少步骤。
目前基本上用GLM4.7了。
全程glm5
你的图片提示“暂无权限访问”
确实可以通过提示词来解决,但是占用的token费用要我来支付。
从我的感受来看,我会更倾向选择支持推理的模型,因为在科研、数学及编码方面的确有一定的优势,至于说专门编程的模型实际上在使用时的差别上没有特别强烈的感受,当你把任务拆分为单个函数时。
GLM5,非常好用
我现在是:大部分时间和GLM-5对话,然后各subagent选择性用不同模型,再定义一下agents.md,写完代码要求iflow调用kimi、minimax、qwen、GLM5都审查一遍代码,只有2个以上的模型通过了代码才能合并提交。现在还有一个nanobot使用qwen负责管理工作列表和确保我不在电脑前的时候我能指挥iflow干活,不过现在调试还没完善,具体玩法等晚上调整好了分享。
经验一 :优先使用最新模型 。GLM5 Kimi2.5 MiniMax2.5
经验2: 模型选择
实际体感来说 Kimi2.5 不管是在速度上 ,还是 详细设计 转 生成代码的需求还原度 都是效果显著。
附加信息:
其他维度横评: (仅供参考,以实际体验为准,我选K2.5)
GLM-5 → 复杂推理与知识可靠性:数学/科学推理评测领先,幻觉控制最好,适合对准确性要求高的知识问答、专业分析场景。
Kimi K2.5 → 多智能体协作自动化:独家 Agent Swarm 能力,最多 100 个子智能体并行、1500 次工具调用,端到端效率提升数倍,适合复杂工作流编排与大规模自动化任务。
MiniMax M2.5 → 高性价比工程编码:SWE-Bench 80.2% 编码正确率最高,速度 100 TPS、成本仅竞品 1/10–1/20,适合追求交付速度和成本控制的日常开发与批量代码生成。
在 iFlow CLI 开发流中,我建议根据以下三个场景进行“无脑切换”:
如果是处理复杂的算法实现、Debug 或是大段的代码重构,DeepSeek-V3.2 依然是性价比和逻辑能力的“守门员”。它的指令遵循能力极强,不会轻易在那儿“胡言乱语”,是生产力的首选。
作为智谱家的新旗舰,GLM-5 的综合素质非常均衡。当你拿不准这个任务该给谁时,选它基本不会出错。无论是中文语境的理解,还是稍微带点创意的任务,它都能给出一个体面的回答,是 iFlow 里最稳的“六边形战士”。
如果你正在通过 iFlow 调试一些需要语气自然、或者包含非常琐碎指令的任务(比如写提示词模板、做内容润色),MiniMax-M2.5 的表现往往会有惊喜。它的人文感更强,不会像有些模型那样有一股浓浓的“AI 翻译腔”。
当你的开发任务涉及查阅几十个 API 文档,或者需要从长长的日志中捞出关键信息时,Kimi 的长文本处理能力依然是核心优势。把背景资料一股脑塞给它,它能比别人更精准地定位到那个“针眼”。
在 iFlow CLI 的日常使用中,我现在的首选是 GLM-5。它最强的地方在于从单纯的代码生成(Vibe Coding)进化到了“系统级工程(Agentic Engineering)”。处理跨文件、长链路的重构任务时,它的稳定性和多工具调用的逻辑闭环比老版本强太多。
如果是纯数学逻辑或者非常刁钻的算法 Debug,我会切到 DeepSeek-V3.2,它的推理深度依然是目前的“守门员”。总之,工具链的尽头是 GLM-5 搞工程,DeepSeek 搞逻辑,稳得不行!
强烈推荐大家在 iFlow 里多试 MiniMax-M2.5。别看它低调,在解决真实的 GitHub Issue(SWE-bench)上表现非常惊人。我最近在做多端(Web+iOS)适配,它的代码补全不只是给个片段,而是能理解我整个 Repository 的架构,生成的 Patch 直接能用。
另外,它生成的 Office 文档能力(Word/Excel)也是个隐藏彩蛋。开发累了直接让它帮忙整理技术文档,效率起飞。一句话:求稳求准选 MiniMax,绝对的实战派首选。
我的模型选择指南:“不仅要能写,还得能看。”
现在的开发任务早就不止是敲代码了。我最常用的组合是 Kimi-K2.5。作为列表里的 1T 参数巨兽,它的多模态(Vision)能力太好用了。iFlow 里遇到 UI 报错或者需要参考视觉设计图写 CSS 时,直接把截图丢给 Kimi,它能瞬间理解视觉反馈并给出修复建议。
加上它那个变态的长文本窗口,几万行的 API 文档塞进去,提问从来不掉链子。调研选 Kimi,工程选 GLM-5,这套组合拳打下来,开发效率直接翻倍!
目前主kimi2.5 有思考,有能力,还是多模态 ![]()