我在想如果把大模型的训练范式改成 元能力+少量必备的通用和编程知识,然后外挂常用编程库用法等技能知识库的方式使用, 能否在保证 处理任务能力的同时,大幅减少 大模型的参数? 因为各个旗舰模型中,我查询后发现有大量训练的知识和内容,但个人使用者常常只会用到一小部分,所以就想了这么一个 核心元能力内置+专项技能外挂”的新范式 ,而现在的工作流框架也能支持这样的工作流程,比如最近兴起的 agentic rag,也可以理解成通过 专项技能外挂让大模型在具体任务中 可以根据最新的情况做出更合理的判断和执行,那么既然大模型永远不可能存储最新的知识, 索性把 精力放到 核心元能力内置 上,然后通过 专项技能外挂 进行赋能, 这样能大幅降低 大模型的训练成本和迭代周期,大幅降低部署成本。 qwen 可否考虑用7B 小模型测试论证 ? 我觉得从 工作流的使用角度,可以反推 对 大模型的核心功能的要求,然后训练大模型。如果能行得通, 应该可以全面节省大量成本的。
我的逻辑是把模型处理任务或工作流的过程 抽象成 元能力+外挂技能知识库 的组合,大模型负责前者,agentic rag 负责后者。 我觉得可以类比大模型推理技术的发展轨迹,从统一架构演变为 预填充 和 解码 这两个阶段, 而最初各家都是不认可这种方式的。后来发现,真香!!
……………………………………………………………………………………………………………………….
以上是今天下午写的,以下是今天晚上刚看到的论文。
https://mp.weixin.qq.com/s/8LhkUvyAUN-E8DDsXR7UHA?scene=1&click_id=94
典型的元能力训练 ,文章结尾说到通用知识任务处理差, 正好用 外挂技能知识库 补全, 和我提出的 “核心元能力内置+专项技能外挂”新范式 完全契合,哈哈哈(^∇^)
以下是和朋友的聊天记录。


*****************************************************************************************
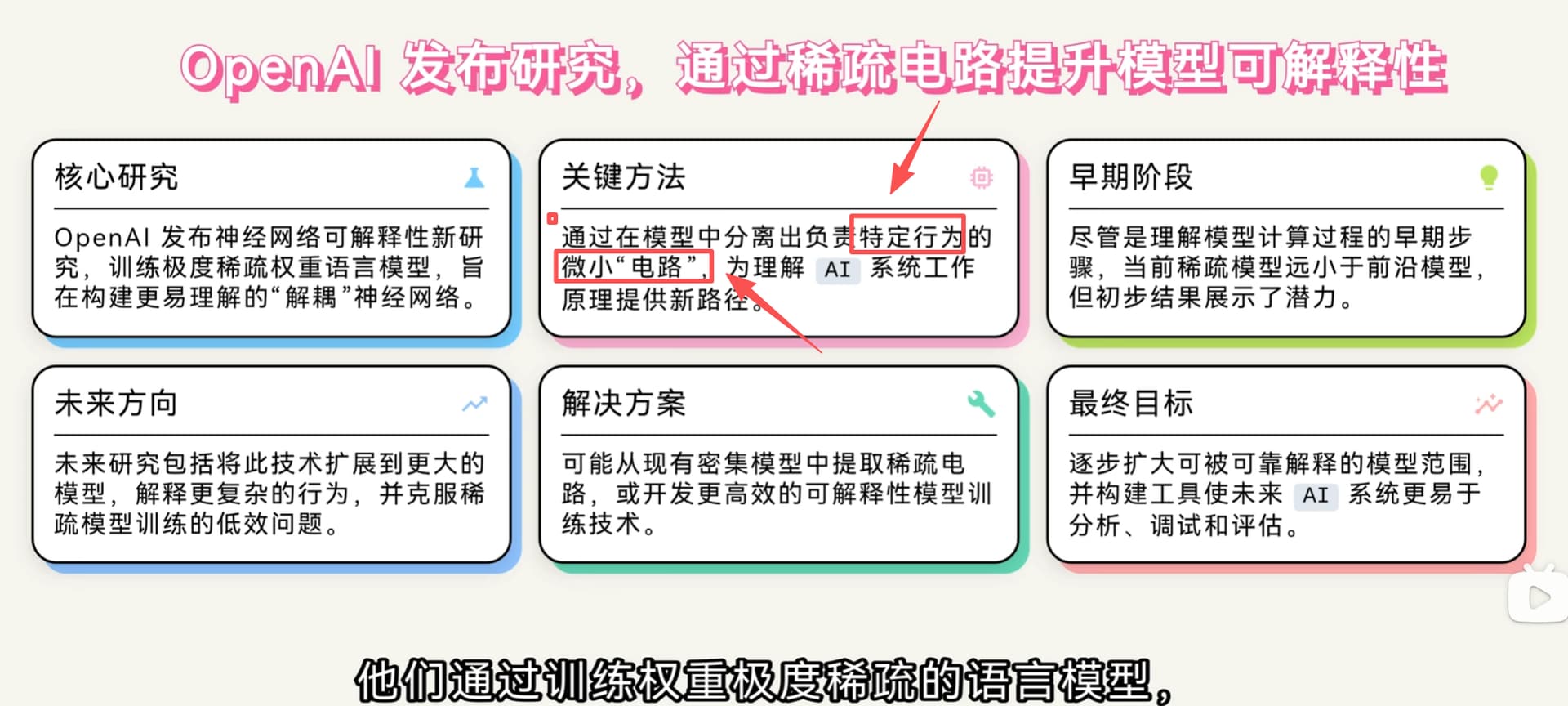
以下是11.16的对话记录,对 openai 微小电路抽离 技术的讨论

也不知道这个帖子能记录到啥时候, 挺有意思的~~~~