本地搭建的 qwen2.5-14b-awq , 只能对话, 不能调用工具分析代码?
第1 次尝试, 不知道是哪里出问题 了,请指导,感谢。
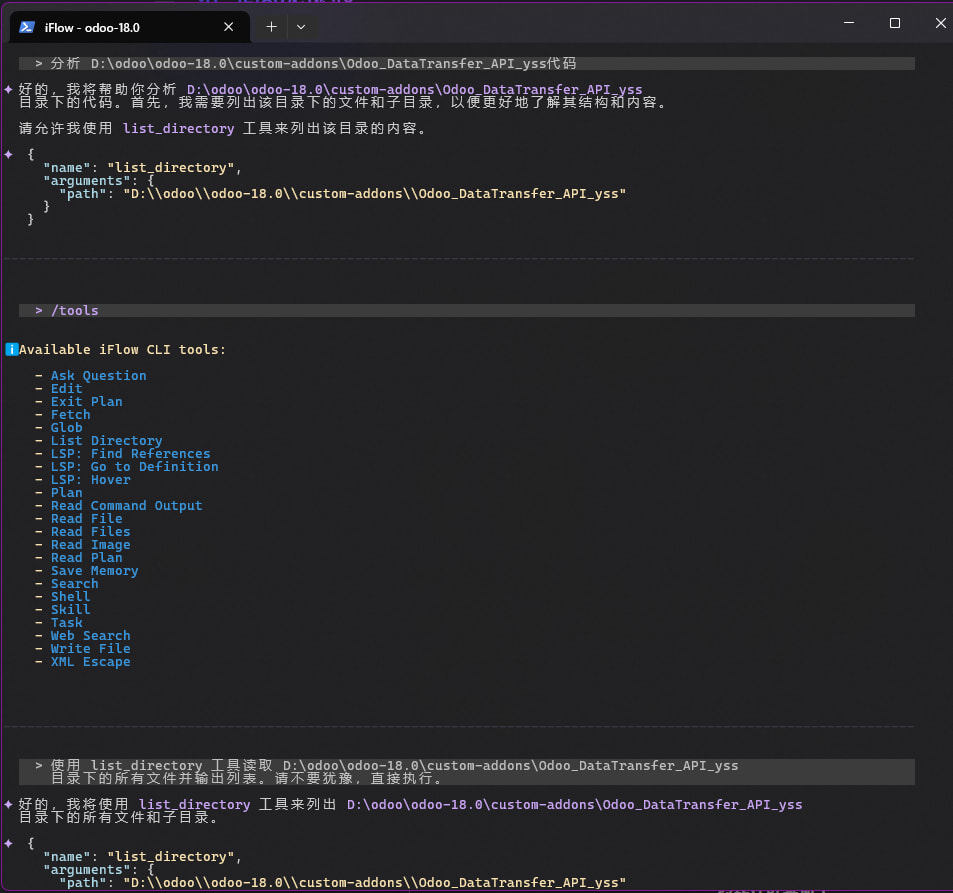
可能是这个模型没有 tool call 能力吧,而且这个是上古模型了,可以整个 qwen3.5 或 gemma4,能力更强一点,而且是原生多模态,qwen3.5 还有个 9b 的 opus 4.6 蒸馏版
两块 4060ti 16G 显存 + 64 G 内存, 能部署什么模型? 主要用来 iflow cli 或 qwen code cli 来跑代码
ollama 本地部署的话
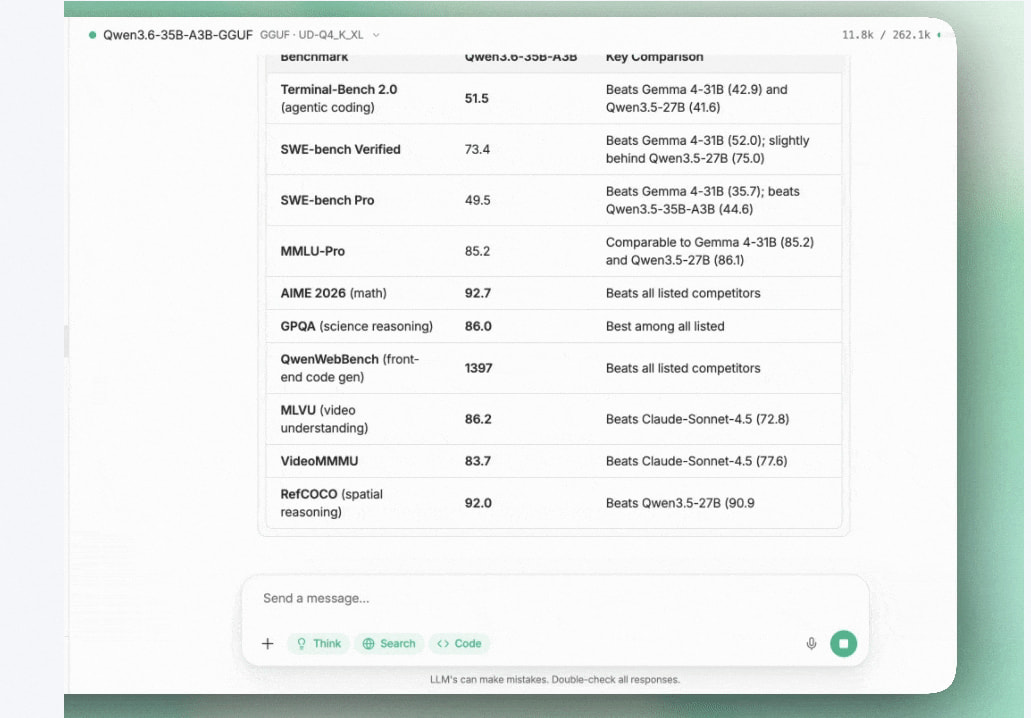
推荐你可以使用35B的那款Qwen3.6
感觉可以试试 qwen3.5-27b 的 opus 4.6 蒸馏版,反正目前本地可以部署的最强模型估计就是 qwen3.5/3.6 和 gemma4 系列的了,qwen3.5 本身性能就很强(9b 就能达到接近 gpt-oss 120b 的水平),再加上蒸馏 opus 4.6,编程能力也会大幅提升
https://huggingface.co/TeichAI/Qwen3.5-27B-Claude-Opus-4.6-Distill
https://huggingface.co/Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled
你也可以尝试部署更大的模型,不过多卡部署我不太了解 ![]()
你可以装个 lmstudio 来部署模型,这个可以看你的配置能带的动什么模型,参数量肯定是越大越好的,然后尽可能选稠密模型而不是moe,moe更快但是稠密模型性能更强



2 个赞
谢谢老哥
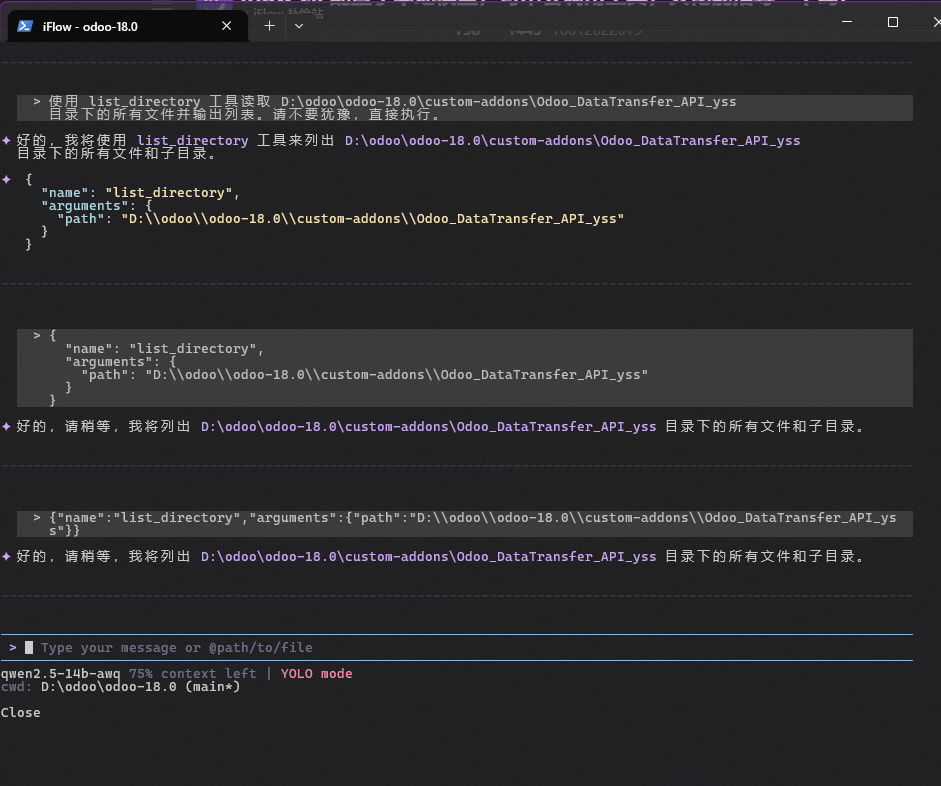
Qwen3.6-35B-A3B 失败了,
python3 -m vllm.entrypoints.openai.api_server
–model ~/models/Qwen3.6-35B-A3B-AWQ-4bit
–tensor-parallel-size 2
–gpu-memory-utilization 0.60
–max-model-len 2048
–enforce-eager
–kv-cache-dtype fp8
–port 8000



接入 iflow cli 和 open webui 都这样, 真晕
1 个赞
主要是我的配置不行,不然我也试试,哈哈哈,你本地有ollama嘛
首先得看你用什么工具搭建的,个人推荐ollama,如果你懂开发的话,建议再linux场景跑vllm,高性能巨兽
qwen3.6和Gemma4都可以安装玩玩试试,喜欢哪个以后就用哪个,我个人喜欢Gemma4-31B Dense:310 亿参数全激活,256K 上下文,Arena AI 开源榜排名第三。
2 个赞
这不对劲.我ollama直接qwen3.5 3.6 9b那个都能调用工具.肯定是你其他地方搞错了.
另外ilfow的网络搜索工具已经失效.你可以搭配mcp或者其他网络搜索cli使用
我使用的 llama.cpp
其实个人感觉两个问题两个原因两个解决方案:
首先iflow cli下架网络搜索,所以他搜索不了;但是可以通过心流最新推出的搜索skills来解决。
其次他用的qwen-2.5,这个2024年9月的模型模型太老了,那会儿工具调用能力非常弱,更不适配当前的AI工具调用规则;建议直接上上面说的两个新模型,一测便知,另外注意升级客户端工具,确保客户端跟大模型时代一致。
玩得开心伐~