一、Free Coding Plan 模型列表
1、美团龙猫
每天5000W lite + 500W thinking tokens**
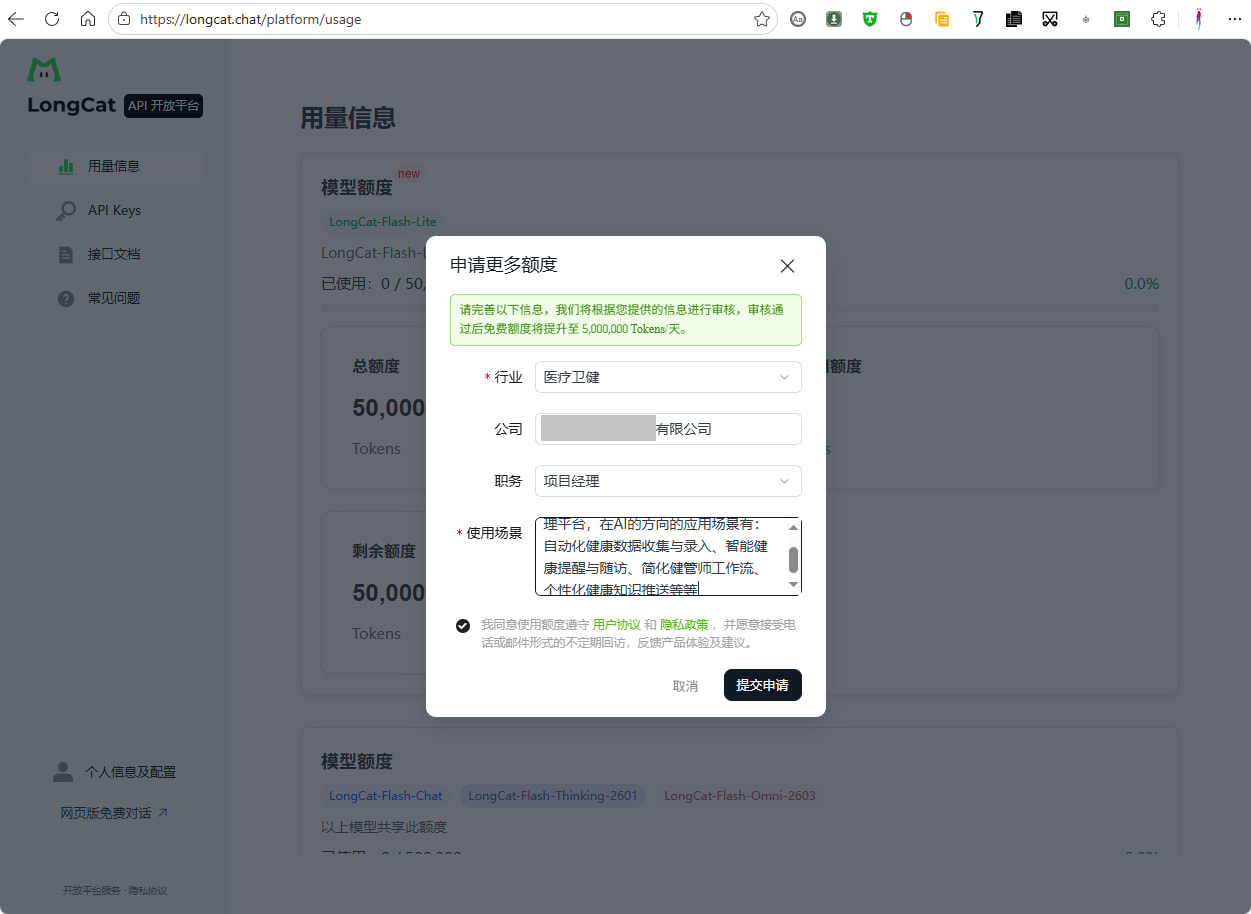
用量看板:https://longcat.chat/platform/usage
baseUrl:https://api.longcat.chat/openai (Anthropic格式:https://api.longcat.chat/anthropic)
LongCat-Flash-Lite 每天独享5000W tokens,其它模型共享每天50W,但通过申请可提升到每天500W
速率限制 仅仅只是用量限制,没有 QPS、QPM|RPM、TPM!
小声说:申请 随便写写,半小时内 一定能给你提升到 500W,2个账号注意不要写同一家公司
网上对这几个模型吹得很历害:美团 lite、thinking 模型 是对标 Claude Opus 的!![]()
一起来看一下吧!
6:LongCat-Flash-Lite 无思考MoE模型:68.5B总参数的高效大语言模型解决方案 - 安全风信子 - 博客园
LongCat-Flash-Thinking 正式发布,更强、更专业,保持极速! - 美团技术团队
LongCat-Flash-Omni正式发布并开源:开启全模态实时交互时代 - 美团技术团队
模型列表:
| 模型id | 模型别名 | 描述 | 最大输出 | 上下文 | 请求限制 |
|---|---|---|---|---|---|
| LongCat-Flash-Chat | longcat-flash-chat | 高性能通用对话模型 | 256k | 256k | 共享500W/天 |
| LongCat-Flash-Omni-2603 | longcat-flash-omni | 多模态模型,创新性集成了高效多模态感知模块与语音重建模块。即便在总参数 5600 亿(激活参数 270 亿)的庞大参数规模下,仍实现了低延迟的实时音视频交互能力,为开发者的多模态应用场景提供了更高效的技术选择。 | 8k | 共享500W/天 | |
| LongCat-Flash-Thinking | longcat-flash-thinking | 在逻辑、数学、代码、智能体等多个领域的推理任务中,达到了全球开源模型的最先进水平(SOTA)。通用推理能力在 ARC-AGI 基准测试中以 50.3 分超越 OpenAI o3、Gemini2.5 Pro 等顶尖闭源模型,ATP 形式推理能力在 MiniF2F-test 基准中的 pass@1 获得 67.6 的分数,大幅领先所有其他参与评估的模型。代码能力在LiveCodeBench 上以 79.4 分显著超越参与评估的开源模型,对标GPT-5,在 OJBench 基准测试中以 40.7 的得分接近 Gemini2.5-Pro 的水平。每秒44 tokens的吞吐率(TPS)。每秒44 tokens的吞吐率(TPS)。 | 256k | 256k | 共享500W/天 |
| LongCat-Flash-Lite | longcat-flash-lite | 高效轻量化MoE模型,总参数量68.5B,激活3B,无思考 在智能体和代码任务上进行了专门优化:优化智能体的推理和决策能力,提升代码理解和生成能力,增强复杂逻辑推理能力,优化多步骤任务的处理能力 。相当快:每秒175 tokens的吞吐率(TPS) | 320k | 256k | 5000W/天 |
不瞒你们说,我已经偷偷用了一个周了(2个号负载均衡),用得不错才来分享的,lite模型 在 Librarian 和 Explore 角色上没有问题(最大输出320k, 250k上下文),thinking模型指令遵循上很不错
thinking模型 我没有设置最大思维链。
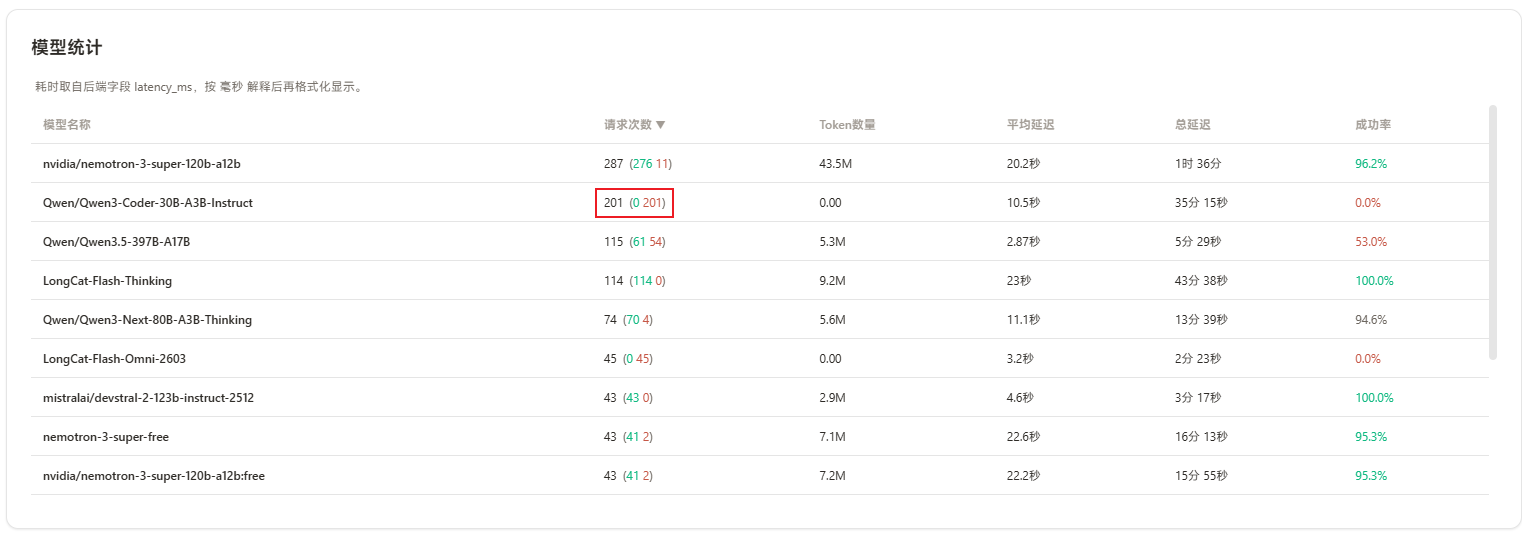
2、NVIDIA 确实很大方!
登录→短信验证时不要选择地区,把 +1 改成 +86 后面跟手机号即可,
请求限制:RPM:40 (实际测试约数,我是用3个号做的负载均衡,因此开发上没卡过)
模型列表:https://build.nvidia.com/models?orderBy=name%3AASC&filters=nimType%3Anim_type_preview
apiKey 申请:https://build.nvidia.com/settings/api-keys
在之前的帖子中 我对它的评测不足,因为我只测了主流模型,但确实 主流的模型 基本都用不了(响应慢到超时),现在我把所有文本模型都测了:(其中的”绝对快“,并非吞吐率TPS,而是响应快,吞吐率下方表格中我也测了)
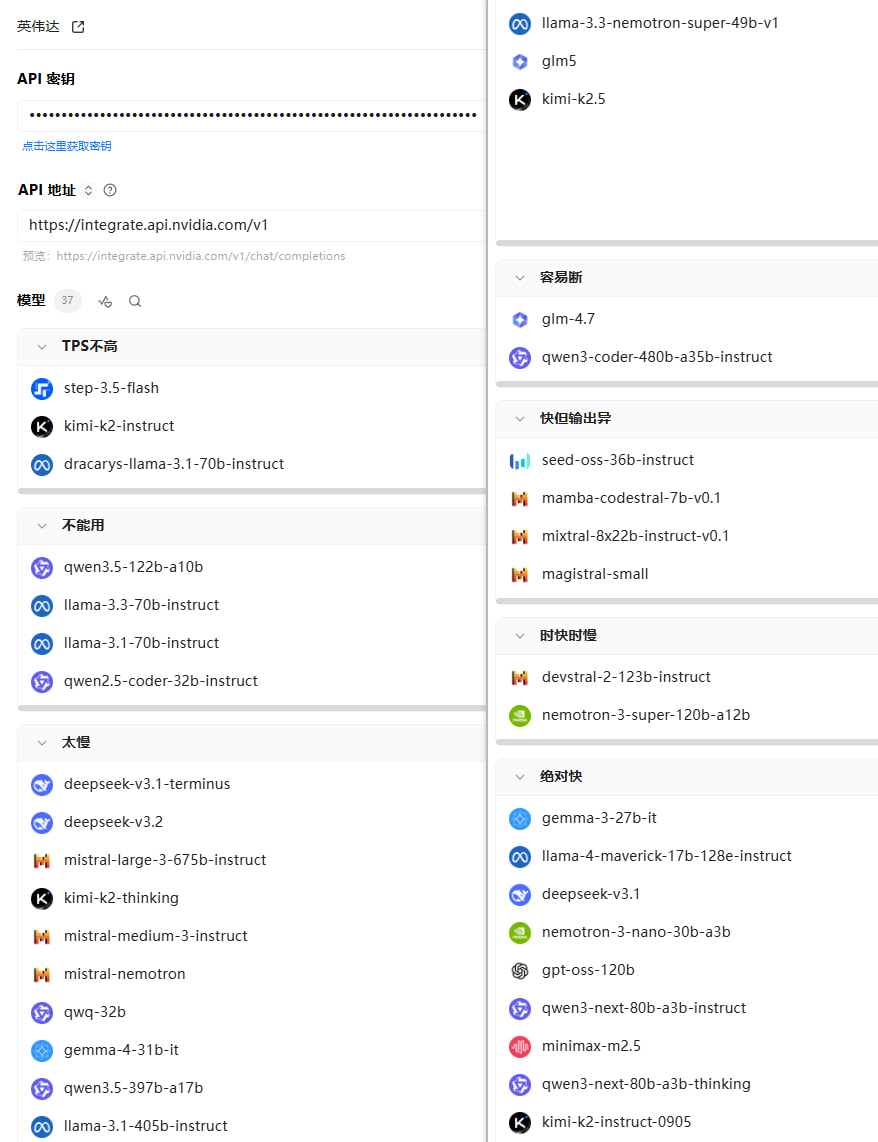
目前能用的:(这不是图片,这是表格,你可以点击右上角全屏查看,复制粘贴拿走~~)
| 模型id | 模型别名 | 描述 | 最大输入 | 最大输出 | 最大思维链长度 | 上下文 | 类型 | TPS |
|---|---|---|---|---|---|---|---|---|
| deepseek-ai/deepseek-v4-pro | deepseek-v4-pro | Agentic Coding 模型,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。针对 Claude Code 、OpenClaw、OpenCode、CodeBuddy 等主流的 Agent 产品进行了适配和优化。 | - | 384k | - | 1m | 文本 | 每秒26 tokens |
| nvidia/nemotron-3-super-120b-a12b | nemotron-3-super-120b-a12b | 一款 120B 参数的开放混合 MoE 模型,激活 12B 参数,编程适用:复杂多步骤任务,需要深度规划与推理的复杂编码任务。需指定思维链长度16384(官方示例中的),否则会过度思考 | 64k | 16k | 1000k | - | ||
| mistralai/devstral-2-123b-instruct-2512 | devstral-2-123b-instruct | Mistral AI 开发的开源智能体编码模型,123B参数密集Transformer模型。支持代码库探索、跨多文件编排更改、跟踪框架依赖、检测故障并重试修正。在 SWE-bench、编码、工具调用和智能体用例方面达到SOTA水平。 | 262k | 65k | - | 256K | 文本 | 每秒53 tokens |
| nvidia/nemotron-3-nano-30b-a3b | nemotron-3-nano-30b-a3b | 30 B 参数的混合 Mixture‑of‑Experts(MoE)模型,采用 Mamba‑2 与 Transformer 组合,Mamba-2 混合架构在长序列建模上的有效性,使其各项能力领先同等规模(30b-a3b)模型30%左右,代码能力 HumanEval 得分 78.05%。支持思考。不需要指定思维链长度 | - | 32k | - | 256k | 文本,思考 | 每秒228 tokens |
| qwen/qwen3-next-80b-a3b-instruct | qwen3-next-80b-a3b-instruct | 阿里巴巴开发的混合专家(MoE)架构大语言模型,总参数800亿,激活参数约30亿,原生支持262144 tokens上下文长度,支持中文深度优化和企业级安全功能。 | 256k | 16k | - | 256k | 文本 | 每秒90 tokens |
| stepfun-ai/step-3.5-flash | step-3.5-flash | Step 3.5 Flash 是 StepFun 最强大的开源基础模型。基于稀疏混合专家(MoE)架构,每令牌仅激活其 1960 亿参数中的 110 亿参数。SWE-bench Verified 取得 74.4%,Terminal-Bench 2.0取得 51.0%,xbench-DeepSearch(2025.05)评测中获得83.7分,证明其在复杂编程和命令行任务中的强大能力。建议指定思维链长度,否则复杂任务思考时长会长达6分钟 | 256k | 66k | - | 256k | 文本 | 每秒50 tokens |
| minimaxai/minimax-m2.5 | minimax-m2.5 | 原生 Spec 能力(在编码前自动拆解需求,生成架构图与功能模块规划,接近人类架构师思维) 工具调用增强,多编程语言支持(代码生成质量接近生产级) 编程效率 对标 GPT-4 Turbo。建议指定思维链长度,否则复杂任务思考时长会长达30多秒。 | 192k | 128k | - | 200k | 文本,思考 | - |
| openai/gpt-oss-120b | gpt-oss-120 | gpt-oss-120b 是 OpenAI 推出的开源权重、1170 亿参数的混合专家(MoE)语言模型,专为高推理、智能体和通用生产用例而设计。每次前向传递激活 51 亿参数,并针对单个 H100 GPU 运行进行了优化,支持原生 MXFP4 量化。性能表现超越 OpenAI o3‑mini,对标 OpenAI o4-mini 。 不需要指定思维链长度 | 128k | 4k | - | 128k | 文本,思考 | 每秒214 tokens |
上述 deepseek-v4-pro 不是很稳定:auth_unavailable: no auth available (providers=nvidia, model=deepseek-v4-pro)
还有3个也能用,响应快,但是吞吐率TPS很低:
| 模型id | 模型别名 | 描述 | 最大输入 | 最大输出 | 上下文 | 类型 | |
|---|---|---|---|---|---|---|---|
| abacusai/dracarys-llama-3.1-70b-instruct | dracarys-llama-3.1-70b-instruct | 基于 Llama-3.1-70B-Instruct 的指令微调版本,由 Abacus.ai 优化。具备多语言理解与生成能力,特别针对复杂推理、代码生成、数学问题等场景优化。保留原生 Llama 3.1 的高性能,同时通过指令微调增强交互体验。很慢:每秒12 tokens的吞吐率(TPS) | 128k | 8k | 128k | 文本 | |
| deepseek-ai/deepseek-v3.1 | deepseek-v3.1 | 相比上一版解决了一系列问题:语言一致性: 缓解了中英文混杂、偶发异常字符等情况;Agent 能力: 进一步优化了 Code Agent 与 Search Agent 的表现,每秒22 tokens的吞吐率(TPS) | 96k | 64k | - | 128k | 文本 |
| moonshotai/kimi-k2-instruct | kimi-k2-instruct | 基于 DeepseekV3 架构的稠密-稀疏混合专家语言模型,总参数 1T、激活 32B,采用 MLA 注意力+ SwiGLU 激活;原生 FP8 量化,支持工具调用与长文档分析;在 vLLM、SGLang 上可直接部署,兼顾高精度与高效推理。每秒16 tokens的吞吐率(TPS) | 128k | 4k | - | 128k | 文本 |
3、OpenRouter
需要充值10美元才能 1000次/天 调用,否则只能50次/天,调用免费模型还有个限制:QPM:20(每分钟最多请求20次)
免费额度:每天 50 次。充值10美元才能 1000次/天 调用,且 RPM + 10
速率限制:每分钟 20 个请求。账户积分数量 = 每秒请求数。RPM:20
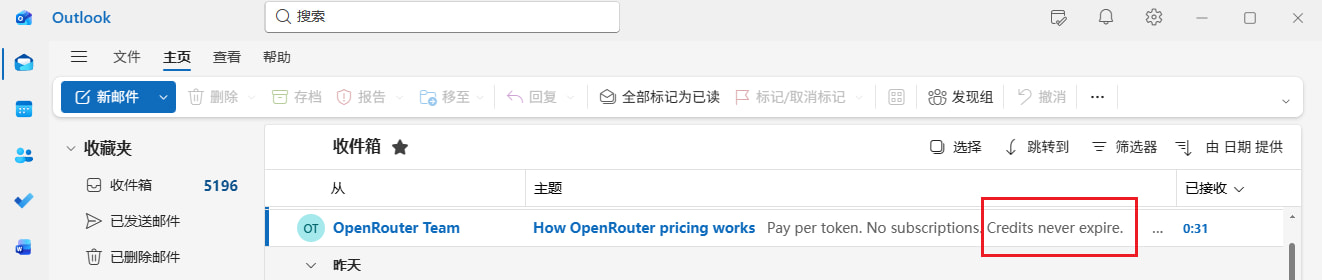
对充值后一年后还没用的 Credits 不会做过期处理,官方在邮件里已经承诺
免费模型列表:https://openrouter.ai/models?fmt=cards&max_price=0&output_modalities=text
10万积分网络搜索免费送:https://openrouter.ai/workspaces/default/byok?tab=web-search
用量看板:https://openrouter.ai/activity
模型id中 **带 :free 是永久免费的,官方文档中有说明。**模型id不带:free 但是价格免费的,都是限时免费,比如之前的 qwen3.6-plus 已经没了。
对充值后一年后还没用的 Credits 不会做过期处理,官方在邮件里已经承诺,这个你们不用担心,我已经截图:(我两个号各充了10美元 → ¥148.38**)**
我测试了它所有免费模型(文本类),它的免费模型很少,真的很少,而且 和 NVIDIA 一样,主流模型 基本不能用,会直接报 429 请求速率限制,哪怕你是开号第1次请求
目前能用的只有3个:
| 模型id | 模型别名 | 描述 | 最大输入 | 最大输出 | 最大思维链长度 | 上下文 | 类型 |
|---|---|---|---|---|---|---|---|
| nvidia/nemotron-3-super-120b-a12b:free | nemotron-3-super-120b-a12b | 一款 120B 参数的开放混合 MoE 模型,激活 12B 参数,编程适用:复杂多步骤任务,需要深度规划与推理的复杂编码任务。需指定思维链长度16384,否则会过度思考 | 64k | 16k | 1000k | ||
| nvidia/nemotron-3-nano-30b-a3b:free | nemotron-3-nano-30b-a3b | 30 B 参数的混合 Mixture‑of‑Experts(MoE)模型,采用 Mamba‑2 与 Transformer 组合,Mamba-2 混合架构在长序列建模上的有效性,使其各项能力领先同等规模(30b-a3b)模型30%左右,代码能力 HumanEval 得分 78.05%。支持思考,不需要指定思维链长度 | 32k | - | 256k | 文本,思考 | |
| openai/gpt-oss-120b:free | gpt-oss-120b | gpt-oss-120b 是 OpenAI 推出的开源权重、1170 亿参数的混合专家(MoE)语言模型,专为高推理、智能体和通用生产用例而设计。每次前向传递激活 51 亿参数,并针对单个 H100 GPU 运行进行了优化,支持原生 MXFP4 量化。性能表现超越 OpenAI o3‑mini,对标 OpenAI o4-mini | 128k | 4k | - | 128k | 文本 |
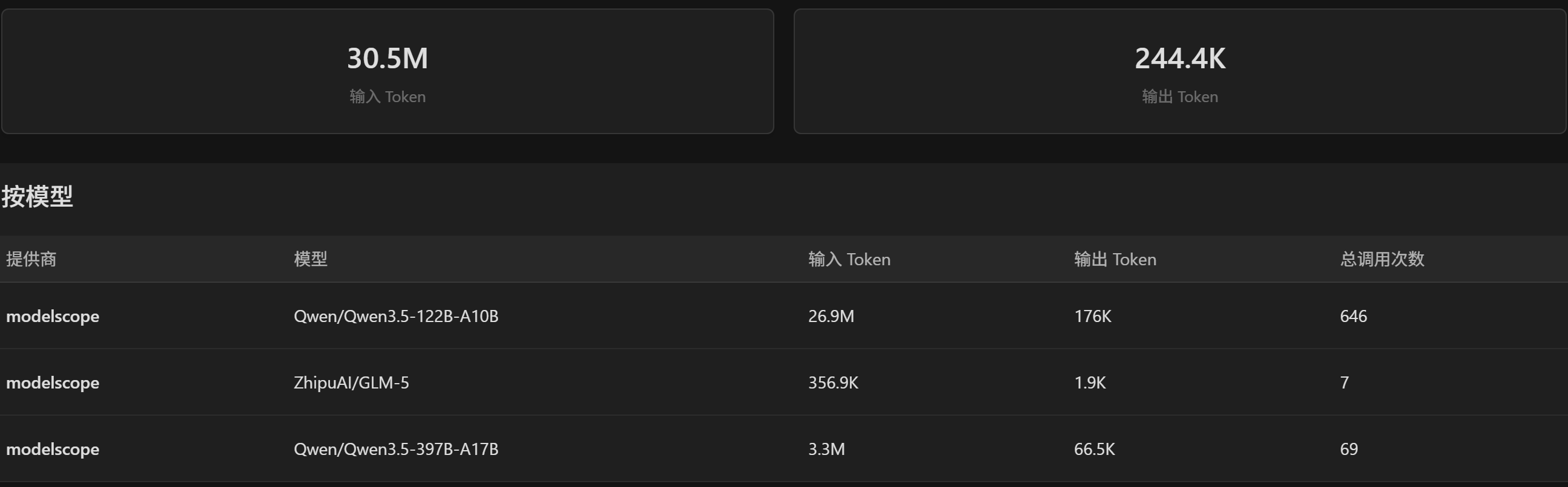
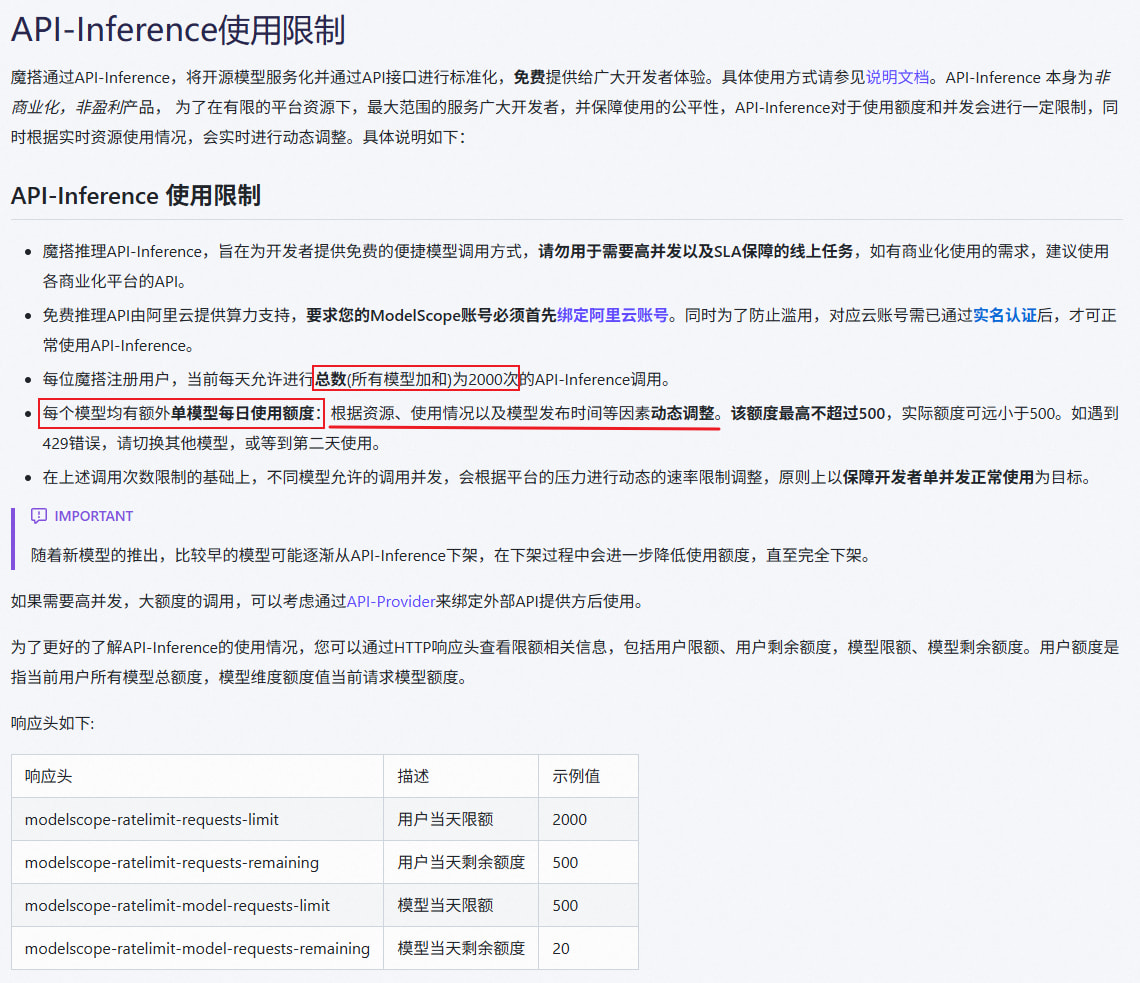
4、魔塔社区
需关联阿里云账号,每天2000次免费调用,单个模型有额外上限
apiKey创建:https://www.modelscope.cn/my/access/token
baseUrl:https://api-inference.modelscope.cn/v1 ( Anthropic 不需要加后缀 /v1)
在之前的帖子中 我也是对它的评测不足,因为我只测了主流模型,但确实 主流的模型 基本都用不了(明明隔了一天都没用,就直接报429 请求速率限制)
但同样地,非主流模型 可用于开发的也是不少的:(kimi-k2.5除外,我实在不能不用)
我测了所有文本模型(上下文少于128k的除外),能用的如下:
- qwen3-14b 必须指定 maxTokens 为8192,否则 会报错
- qwen3-235b-a22b-thinking 必须指定 上下文 content 为 126976,否则 会报错
- 不能用:glm-5,glm-4.7,glm-4.6,glm-4.5,DeepSeek-R1-Distill-Llama-70B
- 可用但低智:Qwen3-30B-A3B-Instruct、Qwen3-30B-A3B-Thinking
- 速率(TPS)低:Qwen/Qwen3.5-27B、qwen3.5-397b-a17b
| 模型ID | 模型别名 | 描述 | 最大输入 | 最大输出 | 最大思维链长度 | 上下文 | 类型 | TPS |
|---|---|---|---|---|---|---|---|---|
| MiniMax/MiniMax-M1-80k | minimax-m1 | MiniMax-M1 是一款开源的超大规模语言模型,拥有约 4560 亿总参数,激活约 45.9 亿参数,采用混合专家(MoE)架构、Flash Attention 和 CISPO 优化算法,支持最高 100 万 token 的输入上下文和最高 80 k token 的输出,实现高效长上下文推理。 | 1000k | 80k | - | 1m | 文本,思考 | 每秒11 tokens |
| Qwen/Qwen3-Coder-480B-A35B-Instruct | qwen3-coder-480b-a35b-instruct | 由 Qwen 团队开发的混合专家(MoE)代码生成模型。它针对智能体编码任务进行了优化,例如函数调用、工具使用和仓库的长上下文推理。该模型总参数量为 4800 亿,每次前向传递激活 350 亿参数(160 个专家中的 8 个)。 推荐采样参数:temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05 | 200k | 64k | - | 256k | 文本. | 每秒96 tokens |
| Qwen/Qwen3-Coder-30B-A3B-Instruct | qwen3-coder-30b-a3b-instruct | 305 亿参数混合专家(MoE)模型,含 128 个专家网络,每次前向激活约33 亿参数 , 由阿里巴巴通义千问团队开发,专用于高级代码生成与仓库级理解 • 在Agentic Coding、Agentic Browser-Use等复杂任务表现优异 , 支持函数调用、工具集成与结构化输出 , 编码基准测试准确率89%,数学准确率89%,伦理推理准确率**98%* , 适合开发者进行大规模代码重构、API 集成、测试生成等场景。 | 126k | 32k | - | 256k | 文本 | 每秒79 tokens |
| Qwen/Qwen3-Next-80B-A3B-Instruct | qwen3-next-80b-a3b-instruct | Qwen3-Next 系列中的指令调优聊天模型,针对快速、稳定的响应进行了优化,不会留下“思考”痕迹。它面向推理、代码生成、知识问答和多语言使用的复杂任务,同时在对齐和格式化方面保持稳健。 | 126k | 64k | - | 256k | 文本 | 每秒231 tokens |
| Qwen3-Next-80B-A3B-Thinking | qwen3-next-80b-a3b-thinking | 智谱AI推出的一系列超大规模语言模型中的一个,具备800亿参数量(实际激活为30亿),它通过混合注意力机制、高稀疏性的Mixture-of-Experts (MoE) 和多令牌预测 (MTP) 等创新技术,提升推理效率并优化长上下文处理能力。该模型专门支持“思考模式”(Thinking Mode),在复杂推理任务中表现出色,被证明在多个基准测试中优于之前的版本和其它开源模型。 | 126k | 64k | - | 256k | 文本,思考 | - |
| Qwen/Qwen3.5-122B-A10B | qwen3.5-122b-a10b | Qwen3.5系列122B-A10B原生视觉语言模型,基于混合架构设计,融合了线性注意力机制与稀疏混合专家模型,实现了更高的推理效率。该模型的综合表现仅次于Qwen3.5-397B-A17B,文本能力显著优于Qwen3-235B-2507,视觉能力优于Qwen3-VL-235B。 | 254k | 64k | 80k | 256k | 思考、 文本、视觉 | 每秒88 tokens |
| Qwen/Qwen3-235B-A22B-Thinking-2507 | qwen3-235b-a22b-thinking | 主要增强功能如下: 在推理任务上的性能显著提高,包括逻辑推理、数学、科学、编码和通常需要人类专业知识的学术基准——在开源思维模型中取得最先进的成果。 明显更好的通用能力,例如指令遵循、工具使用、文本生成和与人类偏好的一致性。 增强了256K长上下文理解能力。 | 124k | 32k | 80k | 256k | 文本,思考 | 每秒53 tokens |
| Qwen/Qwen3-235B-A22B-Instruct-2507 | qwen3-235b-a22b-instruct | Qwen3-235B-A22B 是 Qwen 系列中最新一代大型语言模型,提供全面的密集模型和混合专家 (MoE) 模型。Qwen3 基于丰富的训练经验,在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展。 | 124k | 32k | - | 256k | 文本 | 每秒59 tokens |
| stepfun-ai/Step-3.5-Flash | step-3.5-flash | Step 3.5 Flash 是 StepFun 最强大的开源基础模型。基于稀疏混合专家(MoE)架构,每令牌仅激活其 1960 亿参数中的 110 亿参数。它是一个推理模型,即使在长上下文中也具有极高的速度效率。相对其他大模型提供商仅开源基础模型,而Step 3.5 Flash 允许开发者直接调用中训练阶段的专项能力模块(如代码生成、工具调用),使模型定制化效率提升40%。在专业评测中,SWE-bench Verified 取得 74.4%,Terminal-Bench 2.0取得 51.0%,xbench-DeepSearch(2025.05)评测中获得83.7分,证明其在复杂编程和命令行任务中的强大能力。 | 256k | 66k | - | 256k | 文本, 图像 | 每秒550-760 tokens |
| moonshotai/Kimi-K2.5 | kimi-k2.5 | Kimi K2.5 在 Agent、代码、视觉理解及一系列通用智能任务上取得开源 SoTA 表现。同时 Kimi K2.5 也是 Kimi 迄今最全能的模型,原生的多模态架构设计,同时支持视觉与文本输入、思考与非思考模式、对话与 Agent 任务。实测测试请求限制太高经常报错,约50次/天 | 224k | 16k | - | 256k | 多模态 | 每秒43 tokens |
| MiniMax/MiniMax-M2.5 | minimax-m2.5 | 原生 Spec 能力(在编码前自动拆解需求,生成架构图与功能模块规划,接近人类架构师思维) 工具调用增强,多编程语言支持(代码生成质量接近生产级) 编程效率 对标 GPT-4 Turbo。在SWE-Bench验证中获得80.2%,Multi-SWE-Bench中51.3%,BrowseComp(含上下文管理)中得分76.3%。经过训练,M2.5 能够高效推理并优化任务分解,在执行复杂智能体任务时表现出极高的速度,完成 SWE-Bench Verified 评估比 M2.1 快 37%,与 Claude Opus 4.6 的速度相当。建议指定思维链长度,否则复杂任务思考时长会长达30多秒。 | 192k | 16k | - | 200k | 文本 | 每秒77 tokens |
| Qwen/Qwen3-235B-A22B | qwen3-235b-a22b | Qwen 系列中最新一代大型语言模型,提供全面的密集模型和混合专家 (MoE) 模型。Qwen3 基于丰富的训练经验,在推理、指令遵循、代理能力和多语言支持方面取得了突破性进展。 | 126k | 16k | 38k | 128k | 文本,思考 | 每秒36 tokens |
| Qwen/Qwen3-14B | qwen3-14b | Qwen3-14B是由阿里云开发的大型语言模型,具有14.8B的参数量,其中13.2B为非嵌入参数,训练数据量显著提升。相比Qwen2.5 instruct模型,其显著增强了推理、代码生成和智能体任务的表现。Qwen3-14B支持思维模式和非思维模式,非思考模式下表现与Qwen2.5相当,思考模式下超越QwQ-32B。并且在多语言支持和指令遵循方面表现出色。 | 32k | 8k | - | 128k | 文本 | 每秒54 tokens |
5、智谱
apiKey查看: 智谱AI开放平台
baseUrl:https://api.z.ai/api/paas/v4
模型列表:https://bigmodel.cn/console/modelcenter/square
免费模型列表:https://docs.bigmodel.cn/cn/guide/models/free
用量余额:https://bigmodel.cn/finance-center/resource-package/package-mgmt
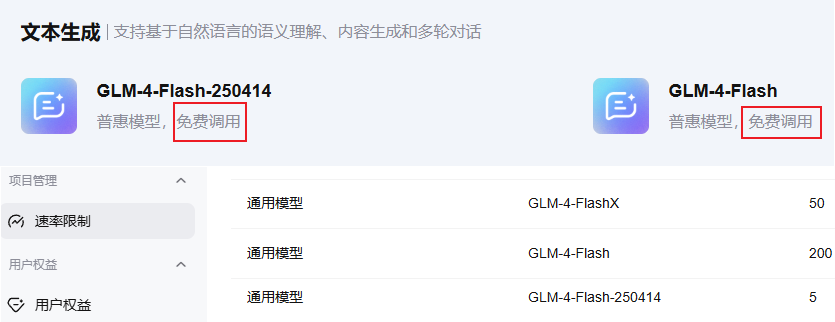
智谱说实话,只有1个模型可用:glm-4-fash,但为了做对比,我还是做个表格,其中黑色粗体进行了说明
| 模型id | 说明 | 模型别名 | 最大输入 | 最大输出 | 上下文 | 最大思维链长度 | 类型 | 请求限制 | 限量 |
|---|---|---|---|---|---|---|---|---|---|
| glm-4.1v-thinking-flash | 在图表/视频理解、前端 Coding、GUI 任务等场景表现出色,核心能力达到全面新 SOTA。模型引入思维链推理机制,显著提升了复杂场景中的回答精准度与可解释性。 不支持工具调用导致经常报错 | glm-4.1v-thinking-flash | - | - | - | - | 多模态 | QPS:5 | 免费 |
| glm-4-flash | 在实时网页检索、长上下文处理、多语言支持等方面表现出色,适用于智能问答、摘要生成和文本数据处理等多种应用场景。适用于 写作建议(情节构思、文字润色、推文、文案)、多语言翻译、结构化数据处理 | glm-4-flash | - | 16k | 128k | - | 文本 | QPS:200 | 免费 |
| glm-4-flash-250414 | - 每次请求都报错 | glm-4-flash | - | 16k | 128k | - | 文本 | QPS:5 | 免费 |
三方文档:
GLM-4.1V-Thinking - 智谱AI开源的视觉语言模型系列 | AI工具集
GLM-4-Flash:智谱AI推出的首个免费API服务,支持128K上下文 - AIHub
二、多账号负载均衡工具
1、Simple-One-Api:
基于GO,one-api 减法,非常推荐
开源地址:https://github.com/fruitbars/simple-one-api
介绍:https://mp.weixin.qq.com/s/ykhTXV0ynmtnkOwNYU3yGQ
推荐用我的,我对它进行了一些修复,提了PR,但是还没有响应
nreg/simple-one-api-fix-cozecn: 修复 cozecn_v3 思考模型 reasoning_content 流式响应
2、CLIProxyAPI:
基于GO,非常推荐
开源地址:https://github.com/router-for-me/CLIProxyAPI
文档地址:https://help.router-for.me/cn/configuration/basic.html
介绍:https://jishuzhan.net/article/2019240010068312066
PS:
这类工具还是蛮多的,我个人只是用了上面2个,非常好上手,当前在用的是 带界面的 CLIProxyAPI,不带界面 的 Simple-One-Api 可以转发 扣子编程 ,不过我测了 扣子编程 确实可以做个智能体,然后 bot_id 做模型id,个人访问令牌 做 api_key 可以实现 外部 api 请求,但是对于我们开发来说,有一个痛点,它是智能体,它只能用 智能体 编程界面的 ”插件“ 做 tools 参数,也就是说 IDE开发工具里的 MCP 它调不了,它会以它的插件覆盖掉 上送的 tools 参数(Simple-One-Api 的 cozecn_v3 的代码 我加上了tools参数,但是无论工作流智能体还是单 agent 智能体 都不能 使用 tools 参数,导致智能体不能调用外部工具,只能使用扣子平台的插件)。
3、类似的工具:
LiteLLM:统一模型服务接口的Python代理库,25k star
开源地址:https://github.com/BerriAI/litellm
官网:https://github.com/BerriAI/litellm
中文版: https://docs.litellm.com.cn/
介绍:
https://mp.weixin.qq.com/s/4W3f3kDSHOL3tKlRNic-Eg
https://mp.weixin.qq.com/s/-N6lMPd4YV5fT2IRZ0Codw
any-llm:统一模型服务接口的Python代理库
开源地址:https://github.com/mozilla-ai/any-llm
介绍:https://mp.weixin.qq.com/s/npUCsz0qoQXK0sAiMjZSWQ
**one-api:**基于GO
开源地址:https://github.com/songquanpeng/one-api
介绍:
https://mp.weixin.qq.com/s/1I9YqUj-7mq9MBsiBeOmHA
https://mp.weixin.qq.com/s/_2p8Srx2tY3FhUDJfnSanw
new-api:(基于GO,one-api 加法)
开源地址:https://github.com/QuantumNous/new-api
介绍:https://mp.weixin.qq.com/s/oO8w5kdqIaDzOuykVtIwaA
4、工具对比
| 项目 | 类型 | 技术栈 | 复杂度 | 核心优势 | 适用对象或场景 | 关键功能 |
|---|---|---|---|---|---|---|
| One-API | 全功能 API 网关 | Go [1] | 高 | 统一接口,一套代码调用多服务商,简化维护;高性能(Go 语言),开箱即用的 UI 专注于运营和管理 [1]。 | 需要商业化分发和成本控制的团队 [1]。 | - 统一 OpenAI 格式接口 - 多渠道负载均衡与失败重试 - 用户/密钥分发 - 预算控制与额度管理 - 支持多机部署 [1] |
| Simple-One-API | 轻量级 API 适配工具 (无Web UI,配置文件驱动) | Go [4] | 低 | 极简专注,开箱即用,特别优化国产免费模型 [4]。 | 个人开发者、快速原型验证 [4]。 | - 兼容多种国产大模型 - 随机负载均衡 - 独立配置各服务的并发/QPS - 支持为每个服务配置代理 [4] |
| CLIProxyAPI | 轻量级 API适配提供商授权 (含Web UI,配置文件驱动) | Go [4] | 低 | 极简专注,开箱即用,特别优化提供商授权 | 个人开发者、快速原型验证 | - 独立配置各服务的并发/QPS - 支持为每个服务配置代理 - 多key统一配置 |
| New-API | 增强版 API 网关 | Java (Spring Boot) [2] | 很高 | 在 One-API 基础上,提供更强的格式转换能力和更多前沿模型支持 [2]。 | 需要 One-API 功能并追求更多高级特性和前沿模型支持的高级用户、团队或公司内部平台 [2]。 | - 完全兼容 One-API 功能 - 高级 API 格式转换 (OpenAI<->Claude等) - 支持 Midjourney, Suno 等新服务 - 现代化 UI 与多语言 - 丰富第三方登录 [2] |
| LiteLLM | Python SDK / 可选代理服务器 | Python [5] | 中 | 模型支持最广(100+),开发者体验极佳,与 Python 生态无缝集成;代理服务器功能强大,支持虚拟密钥、成本跟踪、负载均衡等 [5]。 | Python 应用开发者 [5]。 | - 库模式统一调用 - 代理模式部署独立网关 - 支持100+模型 [5] |
| any-llm | Python SDK (用于开发) | Python [3] | 低 | 轻量级,通过利用官方提供商 SDK 来保证兼容性和可靠性;无需代理或网关服务器,直接与 LLM 提供商通信,降低延迟和数据泄露风险 [3]。 | 希望在代码层面快速切换不同模型、进行原型开发或模型比较的 Python 开发者 [3]。 | - 统一接口调用 OpenAI, Mistral, Anthropic 等主流提供商 - 使用官方 SDK 确保兼容性 - 无代理依赖,直接通信 - 响应格式标准化 [3] |
三、附录
下面是我个人的配置参考就好哈,可以拿去直接体验~
1、OpenCode 配置:
{
"$schema": "https://opencode.ai/config.json",
"plugin": [
"oh-my-openagent@latest"
],
"watcher": {
"ignore": [
"node_modules/**",
"dist/**",
".git/**",
".gitnexus/**",
".idea/**"
]
},
"agent": {
"compaction": {
"mode": "primary",
"model": "nreg/nemotron-3-super-120b-a12b"
},
"summary": {
"mode": "primary",
"model": "nreg/nemotron-3-super-120b-a12b"
},
"title": {
"mode": "primary",
"model": "nreg/longcat-flash-lite"
}
},
"provider": {
"nreg": {
"npm": "@ai-sdk/openai-compatible",
"name": "nreg",
"options": {
"baseURL": "http://192.168.1.108:9090/v1",
"apiKey": "sk-000111222333444555666777888999"
},
"models": {
"longcat-flash-lite": {
"name": "longcat-flash-lite",
"limit": {
"context": 256000,
"output": 320000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"longcat-flash-omni": {
"name": "longcat-flash-omni",
"limit": {
"context": 128000,
"output": 8000
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
}
},
"nemotron-3-nano-30b-a3b": {
"name": "nemotron-3-nano-30b-a3b",
"limit": {
"context": 1048576,
"output": 128000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-235b-a22b-instruct": {
"name": "qwen3-235b-a22b-instruct",
"limit": {
"context": 256000,
"output": 32000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-coder-30b-a3b-instruct": {
"name": "qwen3-coder-30b-a3b-instruct",
"limit": {
"context": 256000,
"output": 32000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-coder-next": {
"name": "qwen3-coder-next",
"limit": {
"context": 256000,
"output": 64000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-next-80b-a3b-thinking": {
"name": "qwen3-next-80b-a3b-thinking",
"limit": {
"context": 129024,
"output": 16000
},
"options": {
"thinking": {
"budgetTokens": 20480,
"type": "enabled"
}
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"hunyuan-lite": {
"name": "hunyuan-lite",
"limit": {
"context": 256000,
"output": 6000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-235b-a22b-thinking": {
"name": "qwen3-235b-a22b-thinking",
"limit": {
"context": 126976,
"output": 32000
},
"options": {
"thinking": {
"budgetTokens": 20480,
"type": "enabled"
}
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"step-3.5-flash": {
"name": "step-3.5-flash",
"limit": {
"context": 256000,
"output": 67584
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
},
"thinking": {
"budgetTokens": 20480,
"type": "enabled"
}
},
"glm-4-flash": {
"name": "glm-4-flash",
"limit": {
"context": 128000,
"output": 32000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"gpt-oss-120b": {
"name": "gpt-oss-120b",
"limit": {
"context": 128000,
"output": 4000
},
"options": {
"thinking": {
"budgetTokens": 8000,
"type": "enabled"
}
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"glm-z1-9b": {
"name": "glm-z1-9b",
"limit": {
"context": 128000,
"output": 32000
},
"options": {
"thinking": {
"budgetTokens": 20480,
"type": "enabled"
}
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"doubao-seed-2.0-code": {
"name": "doubao-seed-2.0-code",
"limit": {
"context": 256000,
"output": 131072
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"minimax-m2.5": {
"name": "minimax-m2.5",
"limit": {
"context": 204800,
"output": 16000
},
"options": {
"thinking": {
"budgetTokens": 20480,
"type": "enabled"
}
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3.5-397b-a17b": {
"name": "qwen3.5-397b-a17b",
"limit": {
"context": 256000,
"output": 64000
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
}
},
"qwen3-14b": {
"name": "qwen3-14b",
"limit": {
"context": 131072,
"output": 8192
},
"maxTokens": 8192,
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-coder-480b-a35b-instruct": {
"name": "qwen3-coder-480b-a35b-instruct",
"limit": {
"context": 256000,
"output": 64000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"devstral-2-123b-instruct": {
"name": "devstral-2-123b-instruct",
"limit": {
"context": 131072,
"output": 66560
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"llama-4-maverick-17b-128e-instruct": {
"name": "llama-4-maverick-17b-128e-instruct",
"limit": {
"context": 1048576,
"output": 128000
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
}
},
"longcat-flash-thinking": {
"name": "longcat-flash-thinking",
"limit": {
"context": 256000,
"output": 256000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"nemotron-3-super-120b-a12b": {
"name": "nemotron-3-super-120b-a12b",
"limit": {
"context": 1000000,
"output": 67584
},
"options": {
"thinking": {
"budgetTokens": 16384,
"type": "enabled"
}
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"longcat-flash-chat": {
"name": "longcat-flash-chat",
"limit": {
"context": 256000,
"output": 256000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"qwen3-next-80b-a3b-instruct": {
"name": "qwen3-next-80b-a3b-instruct",
"limit": {
"context": 256000,
"output": 16000
},
"modalities": {
"input": [
"text"
],
"output": [
"text"
]
}
},
"kimi-k2.5": {
"name": "kimi-k2.5",
"limit": {
"context": 256000,
"output": 16000
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
}
},
"glm-4.1v-thinking-flash": {
"name": "glm-4.1v-thinking-flash",
"limit": {
"context": 64000,
"output": 32000
},
"options": {
"thinking": {
"budgetTokens": 20480,
"type": "enabled"
}
},
"modalities": {
"input": [
"text",
"image"
],
"output": [
"text"
]
}
}
}
}
},
"mcp": {
"context7": {
"type": "local",
"command": [
"npx",
"-y",
"@upstash/context7-mcp@latest"
],
"environment": {
"DEFAULT_MINIMUM_TOKENS": "10000"
},
"enabled": true
},
"chrome-devtools": {
"type": "local",
"command": [
"npx",
"-y",
"chrome-devtools-mcp@latest"
],
"enabled": true
}
}
}
2、OMO 配置:
{
"$schema": "https://raw.githubusercontent.com/code-yeongyu/oh-my-openagent/dev/assets/oh-my-openagent.schema.json",
"background_task": {
"modelConcurrency": {
"nreg/devstral-2-123b-instruct": 5,
"nreg/doubao-seed-2.0-code": 2,
"nreg/gpt-oss-120b": 5,
"nreg/kimi-k2.5": 5,
"nreg/llama-4-maverick-17b-128e-instruct": 5,
"nreg/longcat-flash-chat": 10,
"nreg/longcat-flash-lite": 10,
"nreg/longcat-flash-thinking": 10,
"nreg/nemotron-3-nano-30b-a3b": 5,
"nreg/nemotron-3-super-120b-a12b": 5,
"nreg/qwen3-coder-480b-a35b-instruct": 5,
"nreg/qwen3-next-80b-a3b-instruct": 5,
"nreg/qwen3-next-80b-a3b-thinking": 5,
"nreg/qwen3.5-397b-a17b": 5,
"nreg/step-3.5-flash": 5
},
"providerConcurrency": {
"nreg": 15
}
},
"runtime_fallback": {
"cooldown_seconds": 60,
"enabled": true,
"max_fallback_attempts": 3,
"notify_on_fallback": true,
"retry_on_errors": [
400,
429,
503,
529
],
"timeout_seconds": 30
},
"agents": {
"atlas": {
"model": "nreg/nemotron-3-super-120b-a12b",
"fallback_models": [
"nreg/qwen3.5-122b-a10b",
{
"model": "nreg/qwen3-next-80b-a3b-instruct",
"variant": "low"
},
{
"model": "nreg/qwen3-235b-a22b-thinking",
"variant": "medium"
}
],
"prompt_append": ",始终使用中文回复"
},
"explore": {
"model": "nreg/longcat-flash-lite",
"fallback_models": [
"nreg/step-3.5-flash",
{
"model": "nreg/gpt-oss-120b",
"variant": "low"
}
],
"prompt_append": ",始终使用中文回复"
},
"hephaestus": {
"model": "nreg/nemotron-3-super-120b-a12b",
"fallback_models": [
"nreg/qwen3.5-397b-a17b"
],
"prompt_append": ",始终使用中文回复"
},
"librarian": {
"model": "nreg/longcat-flash-lite",
"fallback_models": [
"nreg/step-3.5-flash",
{
"model": "nreg/gpt-oss-120b",
"variant": "low"
}
],
"prompt_append": ",始终使用中文回复"
},
"metis": {
"model": "nreg/minimax-m2.5",
"fallback_models": [
"nreg/qwen3-235b-a22b-thinking"
],
"prompt_append": ",始终使用中文回复"
},
"momus": {
"model": "nreg/kimi-k2.5",
"fallback_models": [
"nreg/qwen3-235b-a22b-thinking"
],
"prompt_append": ",始终使用中文回复"
},
"multimodal-looker": {
"model": "nreg/qwen3.5-397b-a17b",
"fallback_models": [
{
"model": "nreg/qwen3.5-122b-a10b",
"variant": "medium"
}
],
"prompt_append": ",始终使用中文回复"
},
"oracle": {
"model": "nreg/qwen3-235b-a22b-thinking",
"fallback_models": [
"nreg/qwen3.5-122b-a10b",
{
"model": "nreg/qwen3.5-397b-a17b",
"reasoningEffort": "high"
}
],
"prompt_append": "Focus on architecture decisions, complex debugging, and deep technical analysis. Read-only mode: do not write code,始终使用中文回复"
},
"prometheus": {
"model": "nreg/nemotron-3-super-120b-a12b",
"fallback_models": [
"nreg/qwen3.5-122b-a10b"
],
"prompt_append": ",始终使用中文回复"
},
"sisyphus": {
"model": "nreg/nemotron-3-super-120b-a12b",
"fallback_models": [
"nreg/qwen3.5-397b-a17b",
{
"model": "nreg/qwen3.5-122b-a10b",
"variant": "low"
}
],
"prompt_append": ",始终使用中文回复",
"ultrawork": {
"model": "nreg/qwen3.5-397b-a17b",
"variant": "max"
}
},
"sisyphus-junior": {
"model": "nreg/nemotron-3-nano-30b-a3b",
"fallback_models": [
"nreg/qwen3-coder-30b-a3b-instruct",
{
"model": "nreg/qwen3-next-80b-a3b-instruct",
"variant": "medium"
},
{
"model": "nreg/qwen3-235b-a22b-instruct",
"variant": "high"
},
{
"model": "nreg/qwen3-coder-480b-a35b-instruct",
"variant": "xhigh"
}
],
"prompt_append": ",始终使用中文回复"
}
},
"categories": {
"artistry": {
"model": "nreg/nemotron-3-nano-30b-a3b",
"fallback_models": [
"nreg/longcat-flash-thinking"
]
},
"deep": {
"model": "nreg/qwen3.5-397b-a17b",
"fallback_models": [
"nreg/qwen3.5-122b-a10b",
{
"model": "nreg/qwen3-next-80b-a3b-instruct",
"variant": "low"
},
{
"model": "nreg/qwen3-235b-a22b-instruct",
"variant": "medium"
},
{
"model": "nreg/qwen3-coder-480b-a35b-instruct",
"variant": "high"
}
]
},
"quick": {
"fallback_models": [
{
"model": "nreg/step-3.5-flash",
"variant": "medium"
}
],
"model": "nreg/devstral-2-123b-instruct"
},
"ultrabrain": {
"model": "nreg/qwen3-235b-a22b-thinking",
"fallback_models": [
"nreg/longcat-flash-thinking",
{
"model": "nreg/qwen3-next-80b-a3b-thinking",
"variant": "low"
}
]
},
"unspecified-high": {
"model": "nreg/qwen3.5-397b-a17b",
"fallback_models": [
"nreg/qwen3-next-80b-a3b-instruct",
{
"model": "nreg/qwen3-coder-30b-a3b-instruct",
"variant": "low"
},
{
"model": "nreg/qwen3-235b-a22b-instruct",
"variant": "medium"
},
{
"model": "nreg/qwen3-coder-480b-a35b-instruct",
"variant": "high"
}
]
},
"unspecified-low": {
"fallback_models": [
{
"model": "nreg/qwen3-coder-30b-a3b-instruct",
"variant": "low"
},
{
"model": "nreg/qwen3-next-80b-a3b-instruct",
"variant": "medium"
},
{
"model": "nreg/qwen3-235b-a22b-instruct",
"variant": "high"
}
],
"model": "nreg/nemotron-3-nano-30b-a3b"
},
"visual-engineering": {
"model": "nreg/qwen3.5-397b-a17b",
"fallback_models": [
{
"model": "nreg/qwen3.5-122b-a10b",
"variant": "medium"
}
]
},
"writing": {
"fallback_models": [
"nreg/longcat-flash-chat"
],
"model": "nreg/longcat-flash-lite"
}
}
}
好了小伙伴们,这一套 美团龙猫、英伟达、OpenRouter、魔塔社区 组成的 Free Coding Plan 你们觉得怎么样呢?