系列导航:
- 开篇 · 2026 如何养好 Claude Code(开篇):从养龙虾到养 Claude Code
- 第零篇 · 2026 如何养好 Claude Code(零):ClaudeCode Basics
- 第一篇 · 2026 如何养好 Claude Code(一):核心机制深度解析
- 第二篇 · 2026 如何养好 Claude Code(二):插件生态深度实践
- 第三篇 · 2026 如何养好 Claude Code(三):框架选型指南
- 第四篇 · 2026 如何养好 Claude Code(四):多Agent协作实战
要想养好 Claude Code,首先要理解它的底层机制。
这不是玄学,而是一套精心设计的系统。Anthropic 工程师 Thariq 在分享 Claude Code 构建经验时说过:为 Agent 设计工具是一门艺术,而非科学。
本文将从 Prompt 体系、上下文管理、SubAgent 机制、多模型策略、Context Fork 五个维度,拆解 Claude Code 的核心机制。
一、Prompt 体系:三层提示词架构
刚接触 Claude Code 时,我一直好奇:为什么它有时候"懂我",有时候又像失忆了一样?后来才明白,答案藏在它的 Prompt 体系里。
简单来说:Claude Code 的"记忆"不是铁板一块,而是由多层提示词组成的。有些层很稳定,几乎不变;有些层每轮都会更新。当动态层的信息没有正确传递时,它就会"失忆";而当稳定层的工作流定义清晰时,它的行为就会很"懂你"。
Claude Code 的系统提示词采用分层设计,每层负责不同的职责:
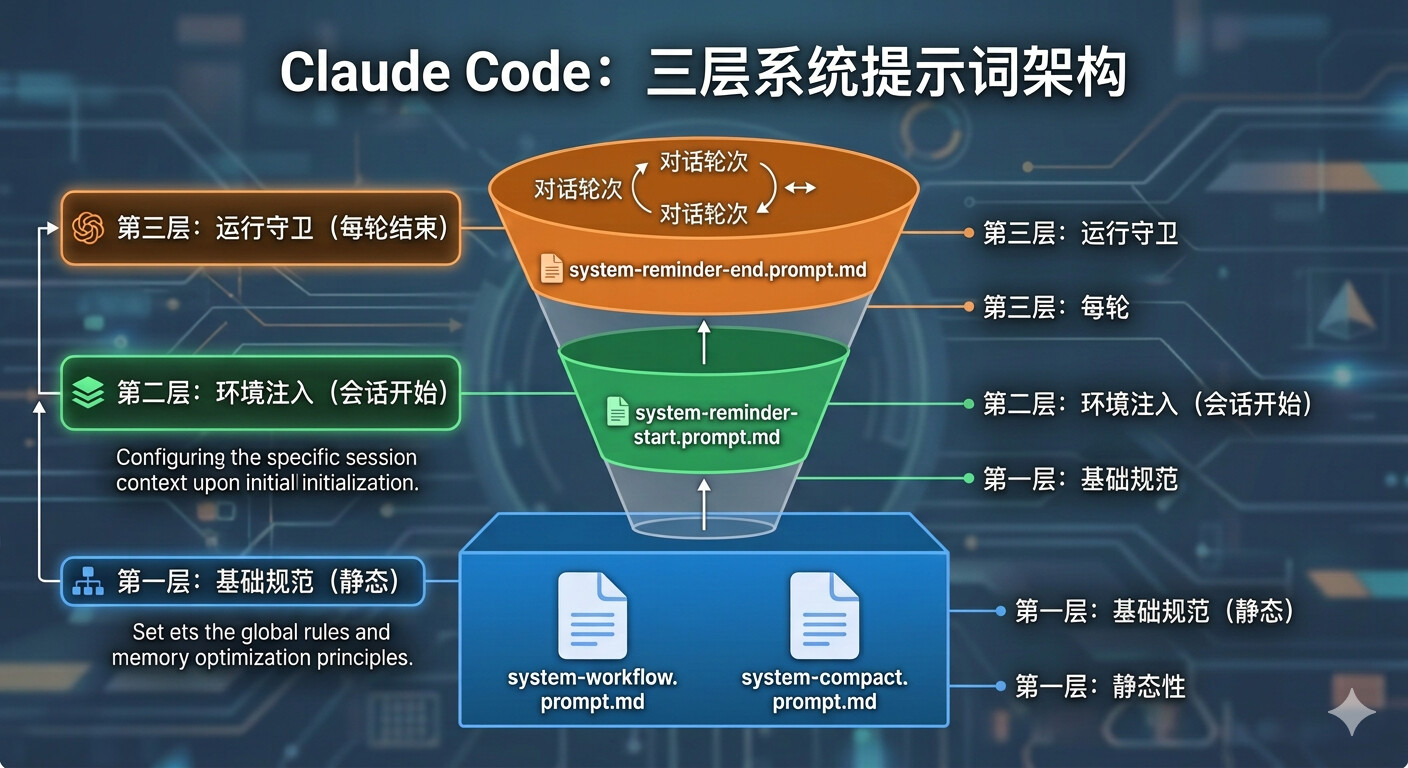
| 提示词文件 | 功能 | 更新频率 |
|---|---|---|
system-workflow.prompt.md |
定义 Agent 行为规范与工作流程 | 极少变化 |
system-compact.prompt.md |
指导上下文压缩的具体指令 | 极少变化 |
system-reminder-start.prompt.md |
初始化时注入环境配置、权限参数 | 会话开始时 |
system-reminder-end.prompt.md |
结束前检查待办事项并记录状态 | 每轮结束时 |
缓存前缀结构
什么是"前缀匹配"?
提示缓存的工作原理是前缀匹配——API 会缓存从请求开始到某个断点之间的所有内容。这意味着:
- 请求的顺序至关重要
- 前缀中任何位置的更改,都会使该位置之后的所有缓存失效
打个比方:
- 缓存就像一叠积木,底部稳定,顶部易变
- 抽掉中间一块?上面全部倒塌(缓存失效)
- 所以:稳定内容放底部,动态内容放顶部
理解了这一点,你就明白为什么要这样排序了:
┌─────────────────────────────────────────┐
│ 对话消息(动态) │ ← 每轮变化,无法缓存
├─────────────────────────────────────────┤
│ 会话上下文 │ ← 会话内有效
├─────────────────────────────────────────┤
│ CLAUDE.md 项目配置 │ ← 随项目更新
├─────────────────────────────────────────┤
│ 系统提示 + 工具定义(静态) │ ← 全局缓存,几乎不变
└─────────────────────────────────────────┘
关键原则:静态内容优先,动态内容最后。前缀中任何位置的更改都会使该位置之后的所有缓存失效。
这对使用者意味着什么?
| 建议 | 原因 |
|---|---|
| CLAUDE.md 保持稳定 | 频繁大改会破坏项目级缓存 |
| 不要手动修改系统提示 | 会破坏全局缓存 |
| 会话中途不要切换模型 | 不同模型缓存不共享 |
| 工具顺序保持一致 | 打乱顺序会破坏缓存 |
一个真实案例:如果在系统提示里放了"当前时间:2026-03-16 10:30",那么每分钟缓存都会失效——因为时间戳变了,整个前缀都要重新计算。
为什么这样设计?
Anthropic 工程师的经验:提示缓存不是事后优化的技巧,而是架构设计的起点。
正如 Thariq 所说:“At Claude Code, we build our entire harness around prompt caching.” 较高的缓存命中率意味着:
- 降低成本:减少重复计算的 token 消耗
- 提升速率限制:缓存命中时服务端压力更小,可提供更宽松的 API 调用配额
Anthropic 内部会持续监控缓存命中率,并将缓存失效视为事故(incident)级别来处理——Thariq 原话是:“Monitor your cache hit rate like you monitor uptime. We alert on cache breaks and treat them as incidents.”
二、上下文管理:动态压缩策略
什么是上下文窗口?
在解释压缩策略之前,先理解一个核心概念:上下文窗口(Context Window)。
简单来说,上下文窗口是模型能"记住"的最大信息量。就像人的短期记忆有容量限制,AI 模型也一样。
Claude Code 的上下文窗口容量约为 200K tokens(约 15 万字)。
┌──────────────────────────────────────────────────────────────────┐
│ Context Window 总容量: 200k │
├──────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┬──────────────┬─────────────────────────────┐ │
│ │ 已使用 │ Buffer │ 空闲空间 │ │
│ │ (消息+系统) │ (预留压缩区) │ (可用于新对话) │ │
│ └─────────────┴──────────────┴─────────────────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────┘
为什么需要压缩?
随着对话进行,会话历史不断增长。当接近窗口容量时:
- 模型无法接收新的输入
- 之前的对话可能被"遗忘"
- 需要压缩来腾出空间
模型的精确性,意图识别能力,以及后续对话的生成质量,都与上下文窗口容量呈反比,下图可以粗略地展示:
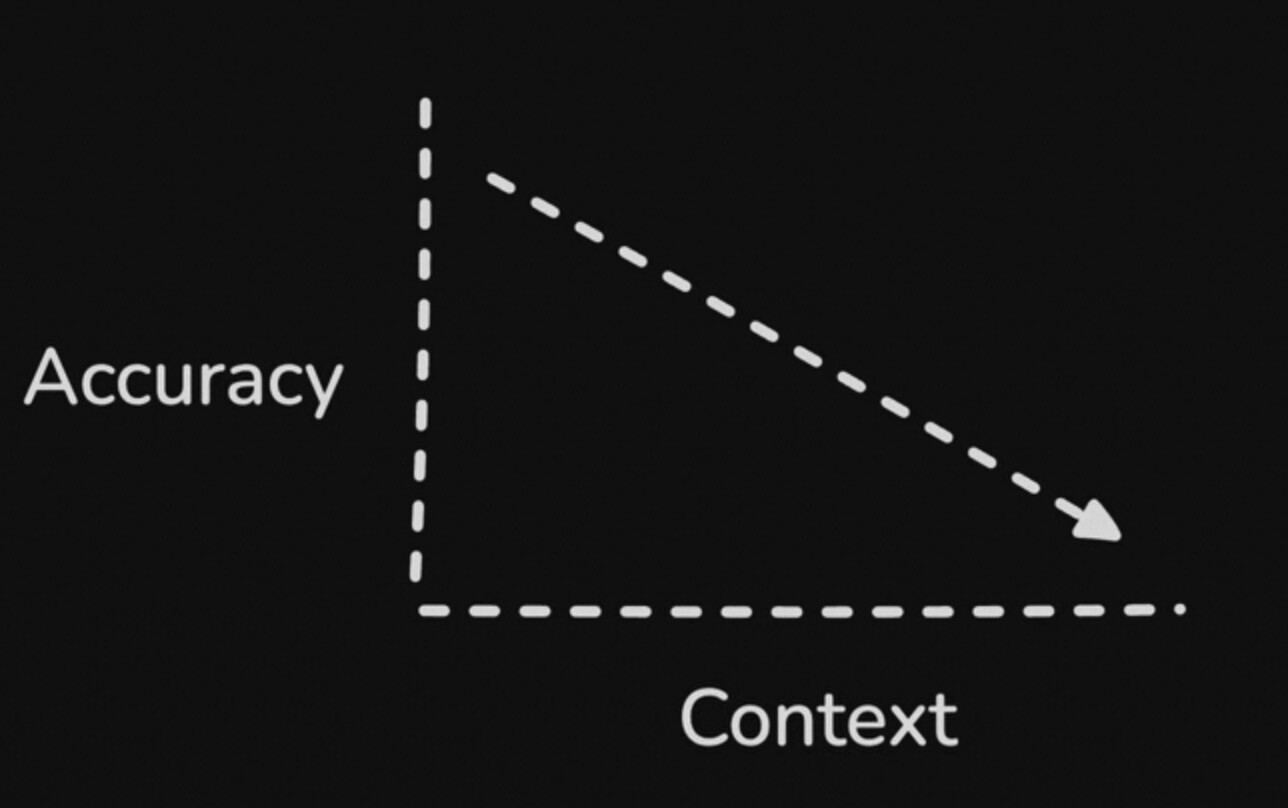
这就像一个会自动整理的魔法书包:当快满时,把旧书压缩成薄纸(只保留要点),腾出空间继续装新书。
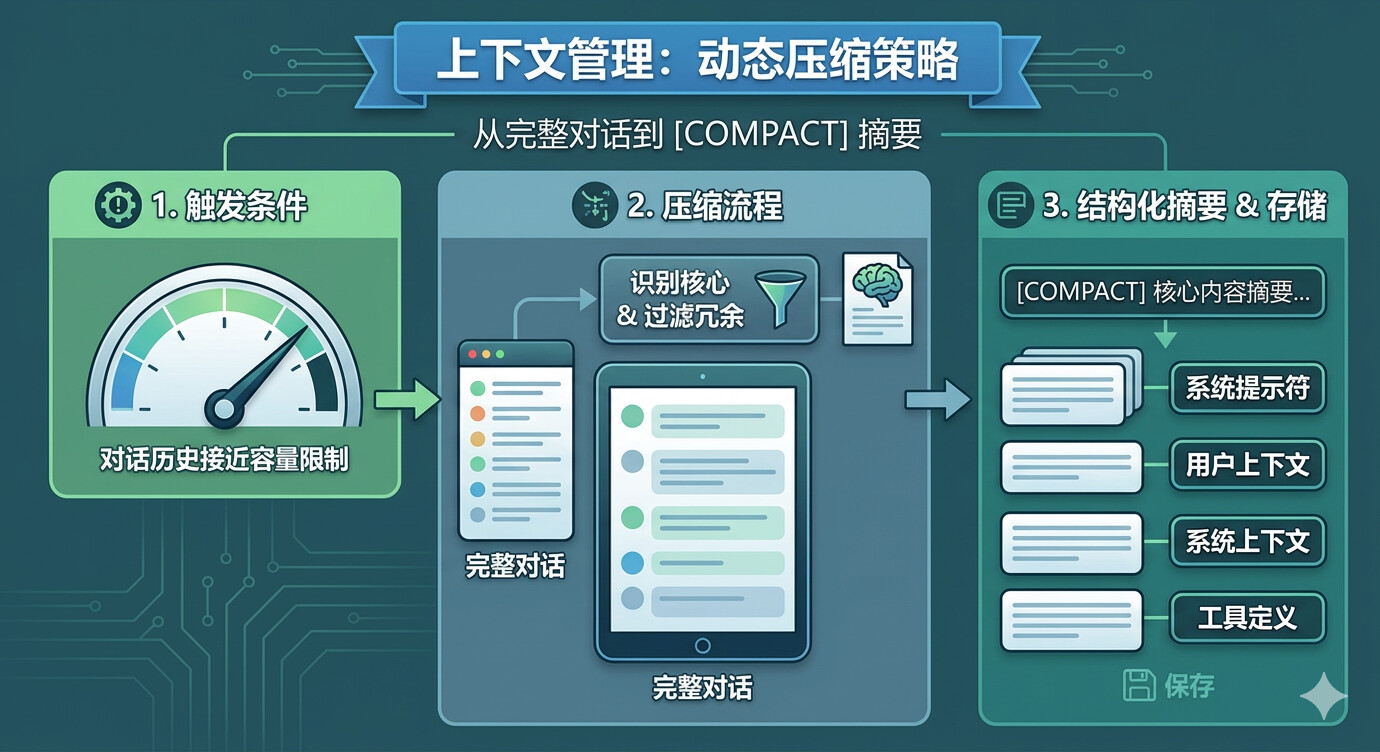
触发条件
当对话历史接近模型上下文容量限制时,压缩机制自动激活。
压缩流程
- 标识核心信息:用户指令、关键决策点
- 过滤冗余内容:中间步骤、重复内容
- 生成结构化摘要:带
COMPACT标记,作为后续对话的初始上下文
缓存安全的压缩实现
压缩操作需要与父会话保持完全相同的:
- 系统提示符
- 用户上下文
- 系统上下文
- 工具定义
从 API 角度看:压缩请求几乎与父级请求的最后一个请求完全相同——相同的前缀、相同的工具、相同的历史记录。因此缓存的前缀被重用,唯一的新 token 是压缩提示本身。
上下文管理最佳实践
| 做法 | 原因 |
|---|---|
| 保持缓存命中 | |
| 最大化缓存复用 | |
| 会破坏缓存 | |
| 会破坏缓存 | |
| 切换模型需要重建缓存 | |
/compact 命令 |
在长对话中手动触发压缩,腾出空间 |
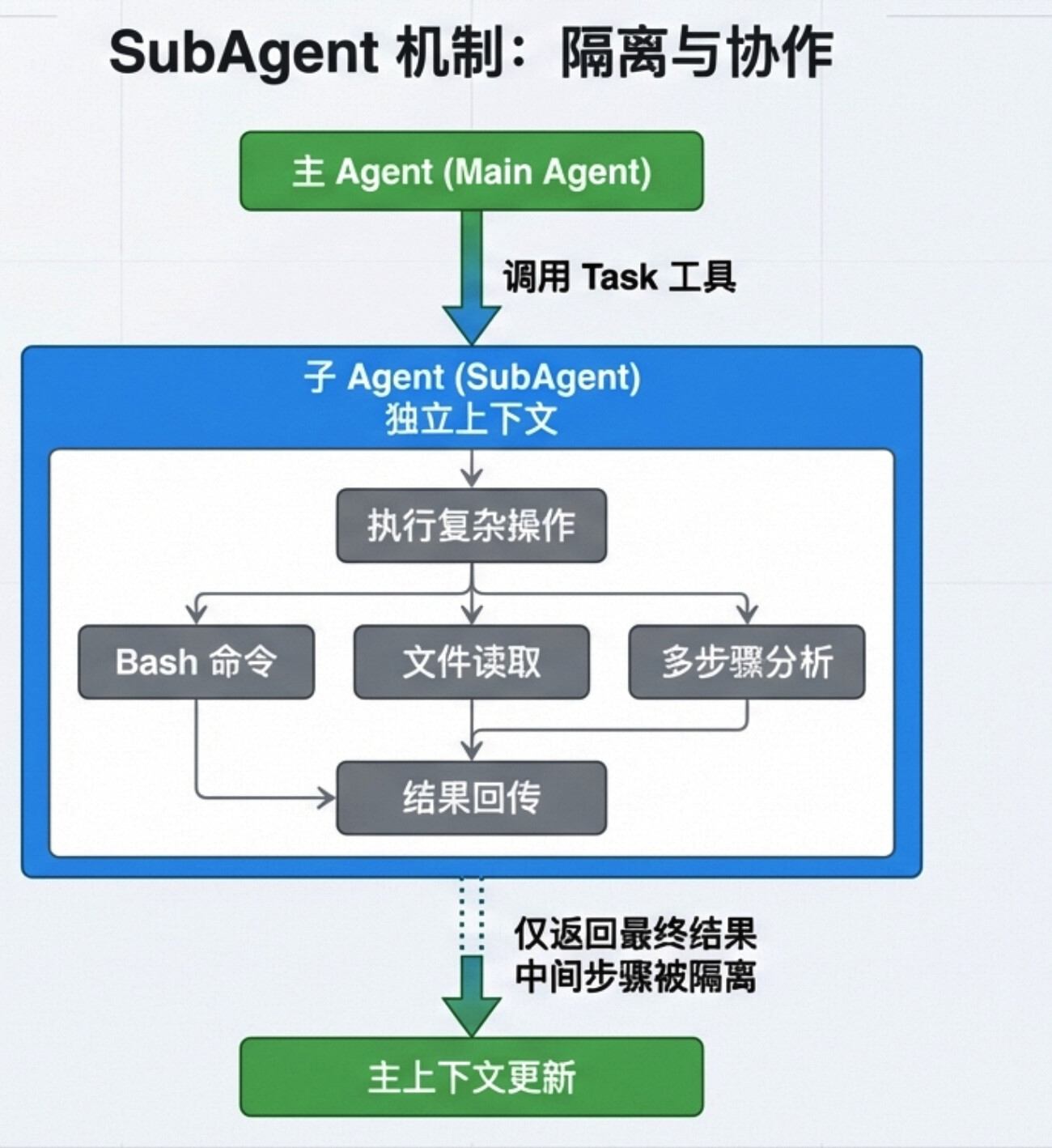
三、SubAgent 机制:隔离与协作
如果说 Claude Code 是一个团队,那 SubAgent 就是它雇"临时工"的方式——让复杂任务不污染主流程。
生活类比:
- 你是项目经理(主 Agent),需要一个文档翻译
- 你不会自己做,而是交给翻译专员(SubAgent)
- 翻译完成后,专员只给你结果,不给你中间查字典的过程
- 你的桌面(主上下文)保持干净
SubAgent 是 Claude Code 实现任务隔离的核心机制。
工作流程
核心优势
| 优势 | 说明 |
|---|---|
| Token 优化 | 主上下文不保存搜索过程,只保留结果 |
| 任务隔离 | 复杂操作不干扰主流程 |
| 并发执行 | 可同时启动多个子 Agent |
| 模型切换 | 子 Agent 可使用不同模型(如 Haiku 4.5 探索代码库) |
典型场景:代码搜索
- 主 Agent 启动子 Agent,传入搜索关键词和路径
- 子 Agent 执行
grep或find命令 - 子 Agent 返回函数定义位置
- 主 Agent 仅保留搜索结果,丢弃命令执行细节
模型切换的正确方式
错误做法:在对话中直接切换模型(会破坏缓存)
正确做法:通过子 Agent 切换模型
- 主 Agent(如 Opus 4.6)准备"交接"消息
- 启动子 Agent 使用 Haiku 4.5 执行快速探索
- 子 Agent 返回结果,主 Agent 继续处理
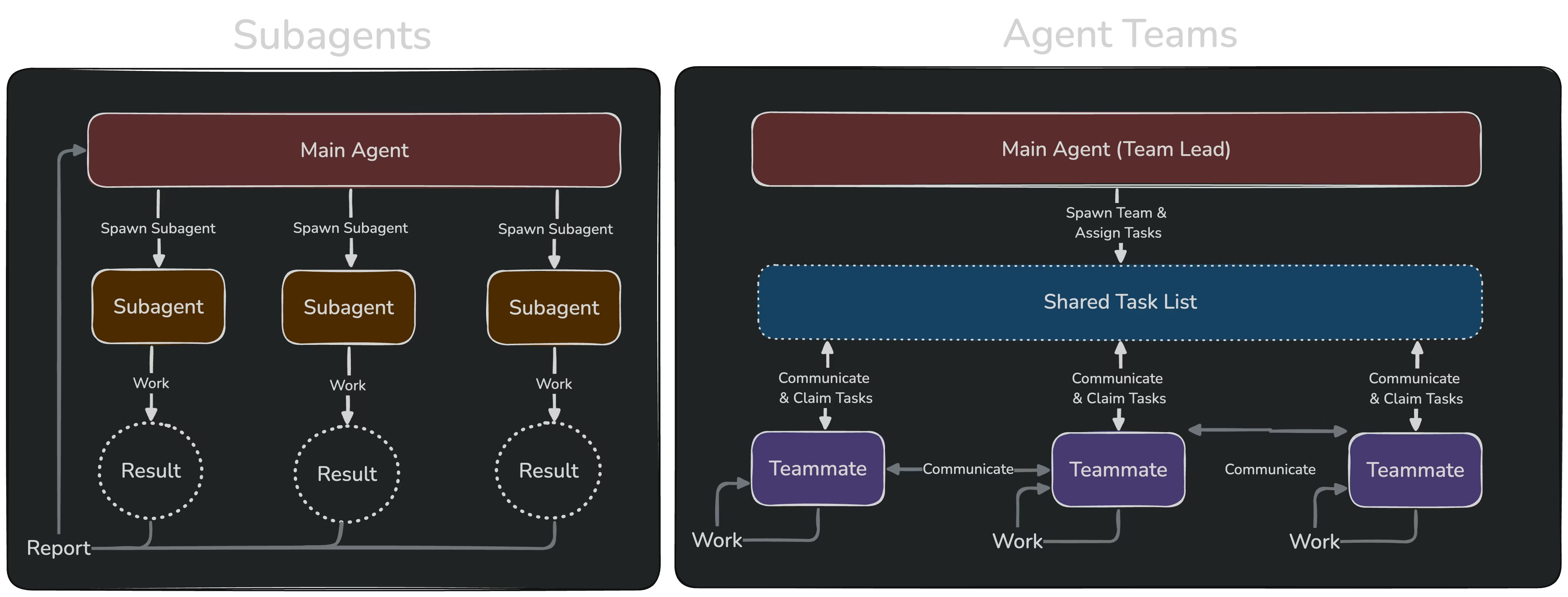
进阶:从 SubAgent 到 Agent Teams
单个 SubAgent 适合简单任务,但如果任务需要多个 Agent 协作呢?这就需要 Agent Teams。
Agent Teams 是 Claude Code 的多 Agent 协作机制,让多个"队友"并行处理复杂任务。我基于这个机制制作了 /multi-agent skill,用于智能分析和优化多 Agent 任务配置。
配合 tmux 的效果:
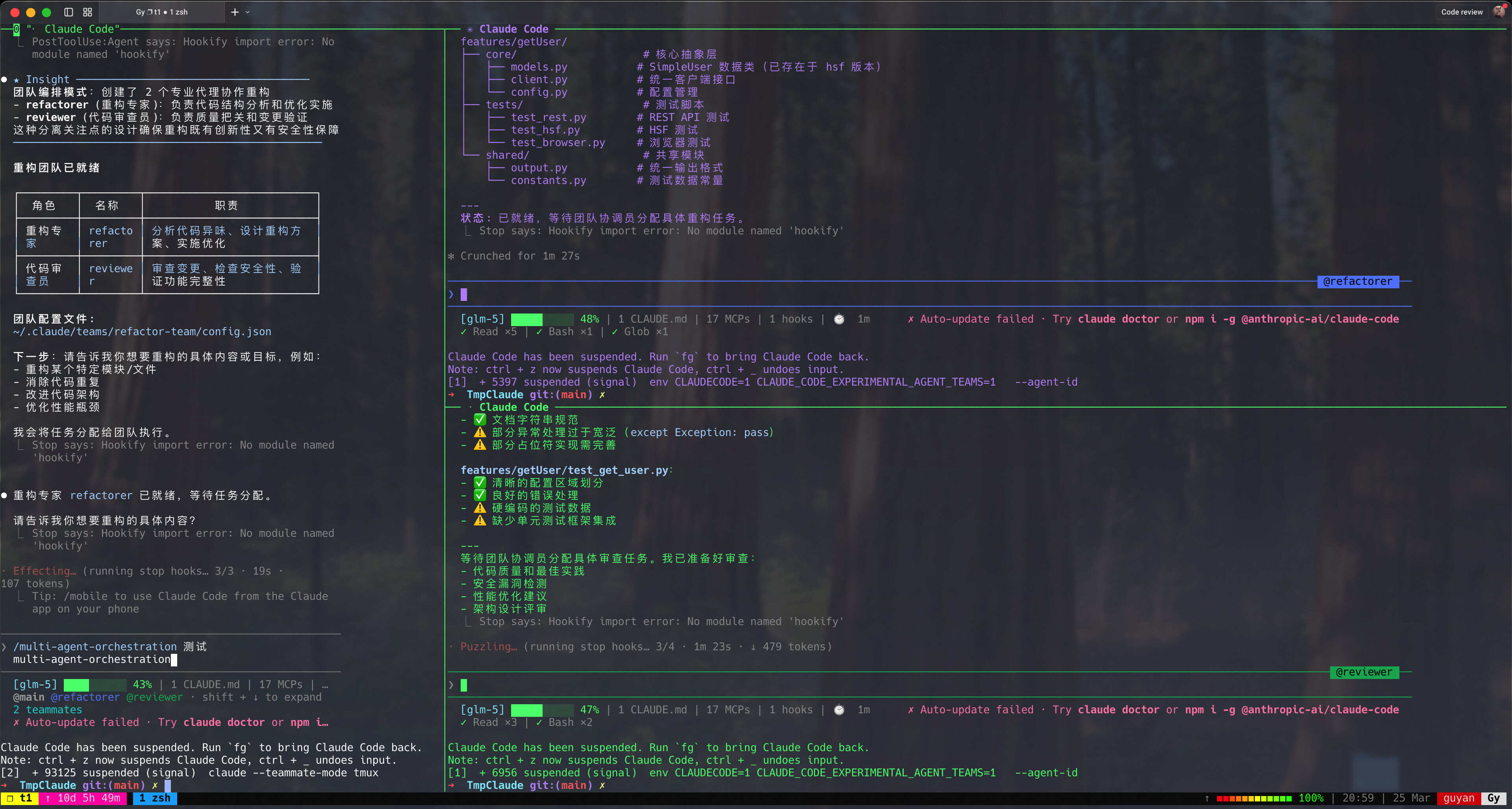
进入 tmux 的 teammate 模式:
claude --teammate-mode tmux
主agent 负责任务拆分,子agent负责任务执行, 如下流程图:
核心功能
| 功能 | 说明 |
|---|---|
| 资源检测 | 扫描已安装的 agents/plugins/tools |
| 智能角色匹配 | 基于任务类型推荐合适的队友 |
| 自适应交互 | 根据复杂度调整交互深度(2-6+步) |
| 方案生成 | 输出可执行的完整 Agent Teams 配置 |
复杂度分级
| 级别 | 条件 | 交互步骤 |
|---|---|---|
| 简单 | 单模块、<3 个队友 | 2-3 步 |
| 中等 | 多模块、3-5 个队友 | 4-5 步 |
| 复杂 | 跨系统、>5 个队友 | 6+ 步 |
使用示例
简单任务:修复登录页面 bug
/multi-agent 修复登录页面的样式问题
中等任务:实现用户认证功能
/multi-agent 实现用户个人中心功能,包括个人信息编辑、头像上传
复杂任务:重构支付系统
/multi-agent 重构支付系统,支持多币种、多种支付方式
比如使用 /multi-agent Skills 进行本教程的并行规划:

ClaudeCode 会加载并读取 /multi-agent Skills, 进行方案生成和智能角色匹配,并对每个角色生成对应的 prompt,并发执行任务

这个 Skills 其实也是我用 ClaudeCode 编写的,安装地址:
multi-agent-orchestration
npx ali-skills add aone-open-skill/multi-agent-orchestration
四、多模型策略:精准匹配任务复杂度
很多人以为 Claude Code 只用一个模型,其实它背后是一个"分工明确的小团队"。
Claude Code 采用多模型分工策略,根据任务复杂度动态选择模型:
| 模型 | 使用场景 | 响应时间 |
|---|---|---|
| Claude Haiku 4.5 | 配额检查、主题分类、简单系统提示处理 | <1秒 |
| Claude Opus 4.6 | 核心流程、代码生成/修改、工具调用、上下文压缩 | 稍慢但更精准 |
任务分配逻辑
graph TB
subgraph 启动阶段
A[开始] --> B[Haiku 4.5: 快速配额检查]
B --> C[Haiku 4.5: 任务分类]
end
subgraph 处理阶段
C --> D{任务复杂度}
D -->|简单| E[Haiku 4.5 处理]
D -->|复杂| F[Opus 4.6 处理]
end
subgraph 优化阶段
E --> G[上下文优化]
F --> G
G --> H[压缩冗余内容<br/>保留关键信息]
end
style B fill:#D4A574,stroke:#b8905a,color:#fff
style C fill:#D4A574,stroke:#b8905a,color:#fff
style E fill:#D4A574,stroke:#b8905a,color:#fff
style F fill:#7BA17B,stroke:#5a8a5a,color:#fff
为什么不随意切换模型?
提示缓存是特定模型独有的。
成本对比示例:如果对话中已使用 10 万 token,现在想问一个简单问题:
- 继续用 Opus 4.6:缓存命中,成本低
- 切换到 Haiku 4.5:需要重建缓存,实际更昂贵
五、Context Fork:Skill 的隔离运行模式
前面介绍了 SubAgent——独立配置的代理,在自己的上下文窗口中运行。但你可能不知道,Skill 也能"变身"为临时工。
这就是 context: fork 的作用。
什么是 Context Fork?
一句话理解:
- 普通 Skill:在你办公室(主上下文)里干活,桌上一堆文件
- Fork Skill:自己去小会议室(隔离上下文)干活,只带结果回来
context: fork 是 Skill frontmatter 中的一个选项。启用后,该 Skill 会在隔离的上下文窗口中运行。
---
name: my-skill
description: "一个示例 Skill"
context: fork # 关键:启用隔离上下文
---
为什么需要 Context Fork?
问题场景:你有一个"代码探索"Skill,需要读取 20 个文件来分析代码结构。
- 不用 fork:20 个文件的内容全部塞进主对话的上下文
- 用 fork:这些内容只在隔离窗口中,主对话保持干净
flowchart LR
A[主对话] --> B{调用 Skill}
B -->|无 fork| C[主对话上下文被污染]
B -->|有 fork| D[隔离窗口执行]
D --> E[只返回摘要给主对话]
style C fill:#da1e28,color:#fff
style D fill:#7BA17B,color:#fff
style E fill:#7B9EC8,color:#fff
Context Fork vs SubAgent
| 维度 | SubAgent | Context Fork |
|---|---|---|
| 定义方式 | 独立配置文件 | Skill frontmatter 选项 |
| 上下文 | 隔离 | 隔离 |
| 适用场景 | 长期重复任务 | 一次性隔离执行 |
| 配置复杂度 | 较高 | 低(一行配置) |
| 返回结果 | 摘要 | 摘要 |
| 场景 | 普通 Skill | Fork Skill |
|---|---|---|
| 需要读取 20 个文件分析代码 | ||
| 简单的格式转换 | ||
| 需要访问主对话历史 |
典型应用场景
- 代码探索:读取大量文件分析结构,只返回关键发现
- 批量重构:在隔离环境中测试重构方案
- 风险评估:分析代码安全风险,不污染主对话
最佳实践
| 做法 | 原因 |
|---|---|
| 防止大量中间输出塞满上下文 | |
| 隔离测试环境,不影响主流程 | |
| 增加开销,得不偿失 | |
| 隔离后无法访问主对话历史 |
六、小结
养好 Claude Code 的第一步,是理解它的核心机制:
| 机制 | 核心要点 |
|---|---|
| Prompt 体系 | 三层分层设计,静态优先动态最后 |
| 上下文管理 | 动态压缩,缓存安全分叉 |
| SubAgent | 任务隔离,Token 优化,支持模型切换 |
| 多模型策略 | Haiku 4.5 轻量任务,Sonnet 4.6 主力任务,Opus 4.6 旗舰任务 |
| Context Fork | Skill 隔离运行,临时 SubAgent |
缓存设计的黄金法则
- 围绕前缀匹配设计系统
- 使用消息而不是修改系统提示
- 不要在对话过程中切换工具或模型
- 像监控正常运行时间一样监控缓存命中率
- 分支操作需要共享父进程的前缀
下期预告
下一篇《插件生态深度实践》将深入:
- Memory 插件:让 Claude 拥有持久记忆
- Hookify 插件:为 Claude 装上"刹车系统"
- Planning with Files:Manus 风格的持久化规划
- 三插件联动实战
思考题
看完这一篇,有兴趣可以试着回答这些问题,看看你的理解程度:
-
上下文窗口的容量是多少?为什么 Claude Code 需要压缩机制?
-
当你在 CLAUDE.md 中频繁修改配置时,会对缓存产生什么影响?如何避免?
-
为什么缓存前缀要按"静态优先、动态最后"排序?如果顺序打乱会发生什么?
-
SubAgent 和 Context Fork 有什么区别?在什么场景下你会选择哪一个?
-
Anthropic 工程师说"提示缓存是架构设计的起点",这句话如何理解?在你的项目中如何应用这个原则?