Ollama’s documentation - Ollama
自从iflow宣布关停以后,我用了几天ollama cloud,发现体验其实挺不错的:
- 速度比隔壁老黄快多了。即便是免费计划,glm 5.1也能用,
速度也还好(我撤回这句话,已经开始卡了 )。
)。 - 限额比较慷慨。
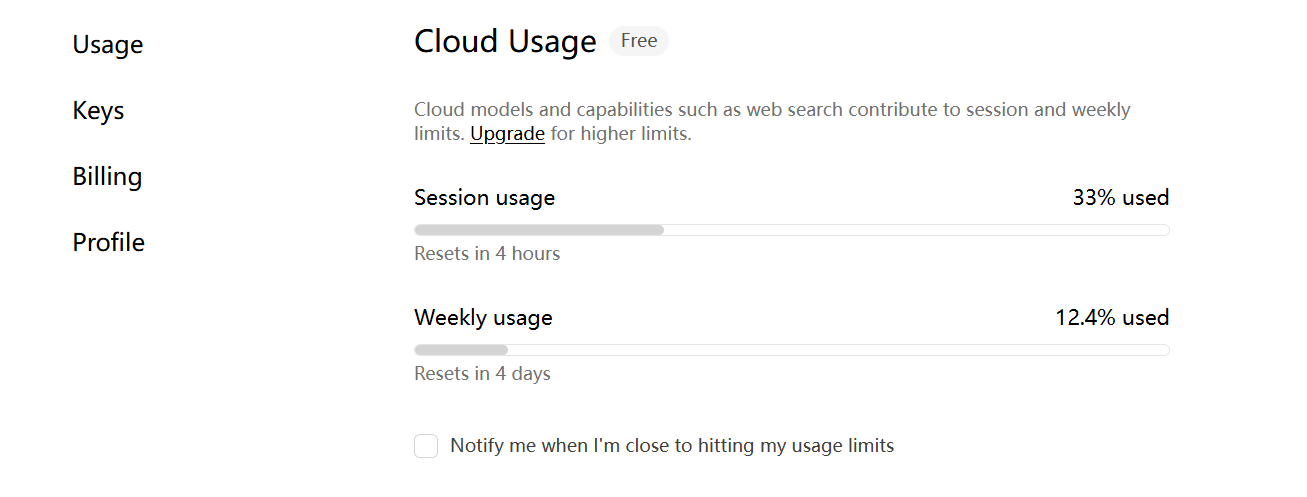
- 免费版轻量级code,大概5h限额不会轻易碰到。
- 付费版(20$一个月)根据官网,是免费版的50倍。用量相当大了可以说。
- (有没有大佬计算一下付费版和coding plan的限额哪个更慷慨?)
- 不压缩、不降智(至少官网这样讲的)
- 根据GPU时间计算额度,而不是请求数或token。这是好事,因为用更轻的minimax、gemma4和qwen3 coder flash,用量会特别多。以及,不用担心输入量大导致费用爆炸,如果缓存命中,GPU时间会很小。
来自官网
What quantization or data format do cloud models use?
Native weights, as released by the model provider. On modern NVIDIA hardware, models may use accelerated data formats supported by Blackwell and Vera Rubin architectures (e.g. NVFP4).
How much more usage does Pro include?
50x more than Free.
How is usage measured?
Usage reflects actual utilization of Ollama’s cloud infrastructure - primarily GPU time, which depends on model size and request duration. Shorter requests and prompts that share cached context use less.This is different from fixed token or request-based plans. Ollama doesn’t cap you at a set number of tokens. As hardware and model architectures get more efficient, you’ll get more out of your plan over time.
我没有说它的性价比一定比国内的plan高,但它的好处在于:不降智,也不太会恶心人。
大家可以去试试免费的plan,玩玩5.1也好,挺聪明的这个模型。
但是是否付费,需要考虑一下。
以上仅为个人的一点点小发现,仅供参考。欢迎各位讨论!
