免费模型有请求速率限制,对于日常使用来说是没问题的,对于我们开发来说总是卡停,我排除了很多家免费模型,最后只剩两家可用,请求限制几乎没有!
一、可用免费模型
1、硅基流动
这是我的邀请连接:https://cloud.siliconflow.cn/i/UrxHjIFT
baseUrl:https://api.siliconflow.cn/v1
apiKey申请:https://cloud.siliconflow.cn/me/account/ak
免费模型列表:https://siliconflow.cn/pricing
可用模型:
| 模型id | 说明 | tags | 类型 | 模型限制 (Level:0) |
|---|---|---|---|---|
| Qwen/Qwen3.5-4B | Qwen3.5是由通义千问团队推出的新一代4B参数多模态大语言模型,集成统一视觉-语言基础架构、高效混合架构和可扩展强化学习技术,原生支持256k上下文长度并可扩展至1,010k;在知识推理、代码生成、多语言理解等任务中表现优异,MMLU-Pro达79.1,C-Eval达85.1,LiveCodeBench v6达55.8,支持图像、视频输入,模型通过早期融合训练实现了统一的视觉语言基础能力,支持文本、图像和视频理解,在同规模模型中表现优异,多项指标超越 GPT-5-Nano 和 Gemini-2.5-Flash-Lite。模型默认启用思考模式(Thinking Mode),支持工具调用,并覆盖 201 种语言和方言 | New, Tools, 视觉, 4B, 256K, 推理模型 | 多模态 | RPM:1000, TPM:80000, |
| Qwen/Qwen3-8B | Qwen3-8B 是通义千问系列的最新大语言模型,拥有 8.2B 参数量。该模型独特地支持在思考模式(适用于复杂逻辑推理、数学和编程)和非思考模式(适用于高效的通用对话)之间无缝切换,显著增强了推理能力。模型在数学、代码生成和常识逻辑推理上表现优异,并在创意写作、角色扮演和多轮对话等方面展现出卓越的人类偏好对齐能力。此外,该模型支持 100 多种语言和方言,具备出色的多语言指令遵循和翻译能力 | 对话, Tools, 推理模型, 8B, 128K, 通用助手, 文案创作, Vibe Coding | 对话 | RPM:1000, TPM:50000, |
| deepseek-ai/DeepSeek-R1-0528-Qwen3-8B | DeepSeek-R1-0528-Qwen3-8B 是通过从 DeepSeek-R1-0528 模型蒸馏思维链到 Qwen3 8B Base 获得的模型。该模型在开源模型中达到了最先进(SOTA)的性能,在 AIME 2024 测试中超越了 Qwen3 8B 10%,并达到了 Qwen3-235B-thinking 的性能水平。该模型在数学推理、编程和通用逻辑等多个基准测试中表现出色,其架构与 Qwen3-8B 相同,但共享 DeepSeek-R1-0528 的分词器配置 | 推理模型, 8B, 128K, 通用助手, 数学推理 | 对话 | RPM:1000, TPM:50000, |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-7B 是基于 Qwen2.5-Math-7B 通过知识蒸馏得到的模型。该模型使用 DeepSeek-R1 生成的 80 万个精选样本进行微调,展现出优秀的推理能力。在多个基准测试中表现出色,其中在 MATH-500 上达到了 92.8% 的准确率,在 AIME 2024 上达到了 55.5% 的通过率,在 CodeForces 上获得了 1189 的评分,作为 7B 规模的模型展示了较强的数学和编程能力 | FIM, Prefix, Tools, 推理模型, 7B, 128K, Math, 通用助手, 数学推理 | 对话 | RPM:1000, TPM:50000, |
| THUDM/GLM-Z1-9B-0414 | GLM-Z1-9B-0414 是 GLM 系列的小型模型,仅有 90 亿参数,但保持了开源传统的同时展现出惊人的能力。尽管规模较小,该模型在数学推理和通用任务上仍表现出色,其总体性能在同等规模的开源模型中已处于领先水平。研究团队采用了与大模型相同的一系列技术进行训练,使其在资源受限的场景中能够实现效率与效果的绝佳平衡,为寻求轻量级部署的用户提供强大选择。特别是在资源受限的场景下,该模型可以很好地在效率与效果之间取得平衡,为需要轻量化部署的用户提供强有力的选择 | Tools, 9B, 128K, 推理模型, 旗舰全能, 长文本处理, RAG | 对话 | RPM:1000, TPM:50000, |
| THUDM/GLM-4.1V-9B-Thinking | GLM-4.1V-9B-Thinking 是由智谱 AI 和清华大学 KEG 实验室联合发布的一款开源视觉语言模型(VLM),专为处理复杂的多模态认知任务而设计。该模型基于 GLM-4-9B-0414 基础模型,通过引入“思维链”(Chain-of-Thought)推理机制和采用强化学习策略,显著提升了其跨模态的推理能力和稳定性。作为一个 9B 参数规模的轻量级模型,它在部署效率和性能之间取得了平衡,在 28 项权威评测基准中,有 18 项的表现持平甚至超越了 72B 参数规模的 Qwen-2.5-VL-72B。该模型不仅在图文理解、数学科学推理、视频理解等任务上表现卓越,还支持高达 4K 分辨率的图像和任意宽高比输入 | 视觉, 9B, 64K, 旗舰全能, 长文本处理, 数学推理 | 对话 | RPM:1000, TPM:50000, |
| PaddlePaddle/PaddleOCR-VL-1.5 | PaddleOCR-VL-1.5 是 PaddleOCR-VL 系列的全新升级版本,在文档解析权威评测集 OmniDocBench v1.5 上取得 94.5% 的精度,超越全球顶尖通用大模型与文档解析专用模型。该版本创新支持文档元素的异形框定位,在扫描、倾斜、屏幕拍摄等真实场景下表现稳健,全面保持 SOTA 性能。同时,模型集成印章识别与文本检测识别任务,关键指标持续领先,推动部署效率与精准度双重提升。 | 对话, 视觉, OCR, 0.9B, 多模态理解 / 识别 | 对话 | RPM:1000, TPM:80000, |
| PaddlePaddle/PaddleOCR-VL | PaddleOCR-VL 是一款专为文档解析设计的 SOTA 且资源高效的模型。其核心组件 PaddleOCR-VL-0.9B 是一个紧凑而强大的视觉语言模型(VLM),它集成了 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型,以实现精确的元素识别。这款创新模型高效支持 109 种语言,在识别复杂元素(如文本、表格、公式和图表)方面表现出色,同时保持极低的资源消耗。通过在广泛使用的公共基准和内部基准上进行全面评估,PaddleOCR-VL 在页面级文档解析和元素级识别方面均达到了 SOTA 性能。它显著优于现有解决方案,与顶级 VLM 相比展现出强大的竞争力,并提供快速的推理速度。这些优势使其非常适合在实际场景中进行部署 | 对话, 视觉, OCR, 0.9B, 多模态理解 / 识别 | 对话 | RPM:1000, TPM:80000, |
| deepseek-ai/DeepSeek-OCR | DeepSeek-OCR 是由深度求索(DeepSeek AI)推出的一个视觉语言模型,专注于光学字符识别(OCR)与“上下文光学压缩”。该模型旨在探索从图像中压缩上下文信息的边界,能够高效处理文档并将其转换为如 Markdown 等结构化文本格式 | 限免, 对话, 视觉, OCR, 3B, 8K, 多模态理解 / 识别 | 对话 | RPM:1000, TPM:80000, |
| tencent/Hunyuan-MT-7B | 混元翻译模型(Hunyuan Translation Model)由一个翻译模型 Hunyuan-MT-7B 和一个集成模型 Hunyuan-MT-Chimera 组成。Hunyuan-MT-7B 是一个拥有 70 亿参数的轻量级翻译模型,用于将源文本翻译成目标语言。该模型支持 33 种语言以及 5 种中国少数民族语言的互译。在 WMT25 国际机器翻译竞赛中,Hunyuan-MT-7B 在其参与的 31 个语言类别中获得了 30 个第一名,展现了其卓越的翻译能力。针对翻译场景,腾讯混元提出了一个从预训练到监督微调、再到翻译强化和集成强化的完整训练范式,使其在同等规模的模型中达到了业界领先的性能。该模型计算效率高、易于部署,适合多种应用场景 | 限免, 对话, Prefix, 7B, 32K, 内容翻译 | 对话 | RPM:1000, TPM:80000, |
| Qwen/Qwen2.5-7B-Instruct | Qwen2.5-7B-Instruct 是阿里云发布的最新大语言模型系列之一。该 7B 模型在编码和数学等领域具有显著改进的能力。该模型还提供了多语言支持,覆盖超过 29 种语言,包括中文、英文等。模型在指令跟随、理解结构化数据以及生成结构化输出(尤其是 JSON)方面都有显著提升 | Deprecated, Prefix, Free, 7B, 32K, 通用助手, 文案创作, Vibe Coding | 对话 | RPM:1000, TPM:50000, |
| internlm/internlm2_5-7b-chat | InternLM2.5-7B-Chat 是一个开源的对话模型,基于 InternLM2 架构开发。该 7B 参数规模的模型专注于对话生成任务,支持中英双语交互。模型采用了最新的训练技术,旨在提供流畅、智能的对话体验。InternLM2.5-7B-Chat 适用于各种对话应用场景,包括但不限于智能客服、个人助手等领域 | Deprecated, Prefix, Free, 7B, 32K, 通用助手, 文案创作, Vibe Coding | 对话 | RPM:1000, TPM:50000, |
| Kwai-Kolors/Kolors | Kolors 是由快手 Kolors 团队开发的基于潜在扩散的大规模文本到图像生成模型。该模型通过数十亿文本-图像对的训练,在视觉质量、复杂语义准确性以及中英文字符渲染方面展现出显著优势。它不仅支持中英文输入,在理解和生成中文特定内容方面也表现出色 | 生图, 图生图, 图像生成, AIGC 内容创作 | 生图 | IPM:2, IPD:400 |
| TeleAI/TeleSpeechASR | 星辰超多方言语音识别大模型是业内首个同时支持普通话+英文+50种方言自由混说的语音识别大模型。模型支持粤语、上海话、四川话等主要方言。模型设计“蒸馏+膨胀”联合训练,解决多场景海量数据训练坍缩问题;设计方言配比因子和“字+标签”的拓展单元,解决方言均衡问题和方言同字不同音问题。星辰超多方言语音识别大模型效果业内领先,在业内知名任务KeSpeech上,达到92.97%准确率;在NIST组织的Babel低资源ASR粤语赛道上,取得目前业内最好结果;在业内知名普通话榜单SpeechIO上,CER 2.63%。目前,星辰超多方言语音识别大模型支持流式和非流式调用 | 语音, ASR, 方言识别, 语音交互(ASR/TTS) | 语音 | RPM:1000, TPM:50000, |
| FunAudioLLM/SenseVoiceSmall | SenseVoice 是一个具有多种语音理解能力的语音基础模型,包括自动语音识别(ASR)、口语语言识别(LID)、语音情感识别(SER)和音频事件检测(AED)。SenseVoice-Small 模型采用非自回归端到端框架,具有非常低的推理延迟。它支持 50 多种语言的多语言语音识别,在中文和粤语识别方面表现优于 Whisper 模型。此外,它还具有出色的情感识别和音频事件检测能力。该模型处理 10 秒音频仅需 70 毫秒,比 Whisper-Large 快 15 倍 | 语音, ASR, 多语言, 语音交互 | 语音 | - |
| BAAI/bge-reranker-v2-m3 | BAAI/bge-reranker-v2-m3 是一个轻量级的多语言重排序模型。它基于 bge-m3 模型开发,具有强大的多语言能力,易于部署,并且推理速度快。该模型采用查询和文档作为输入,直接输出相似度分数,而不是嵌入向量。它适用于多语言场景,特别是在中文和英文处理方面表现出色 | 多语言, 568M, 8K, RAG | 重排序 | RPM:2000, TPM:500000, |
| netease-youdao/bce-reranker-base_v1 | bce-reranker-base_v1 是网易有道开发的双语和跨语言重排序模型,支持中文、英文、日文和韩文。该模型在 RAG 系统中用于精确重排检索结果,可以提供有意义的相关性分数,有助于过滤低质量段落。它针对多种 RAG 任务进行了优化,包括翻译、摘要和问答等。该模型无需特定指令即可使用,具有广泛的领域适应性,已在有道的多个产品中得到验证 | 多语言,279M,512,RAG | 重排序 | RPM:2000, TPM:500000, |
| BAAI/bge-m3 | BGE-M3 是一个多功能、多语言、多粒度的文本嵌入模型。它支持三种常见的检索功能:密集检索、多向量检索和稀疏检索。该模型可以处理超过100种语言,并且能够处理从短句到长达8192个词元的长文档等不同粒度的输入。BGE-M3在多语言和跨语言检索任务中表现出色,在 MIRACL 和 MKQA 等基准测试中取得了领先结果。它还具有处理长文档检索的能力,在 MLDR 和 NarritiveQA 等数据集上展现了优秀性能 | 多语言,1024 维,8K,RAG | 嵌入 | RPM:2000, TPM:500000, |
| netease-youdao/bce-embedding-base_v1 | bce-embedding-base_v1 是由网易有道开发的双语和跨语言嵌入模型。该模型在中英文语义表示和检索任务中表现出色,尤其擅长跨语言场景。它是为检索增强生成(RAG)系统优化的,可以直接应用于教育、医疗、法律等多个领域。该模型不需要特定指令即可使用,能够高效地生成语义向量,为语义搜索和问答系统提供关键支持 | 多语言,768 维,279M,512,RAG | 嵌入 | RPM:2000, TPM:500000, |
2、讯飞星辰
我的邀请链接:https://maas.xfyun.cn/packageSubscription?inviteCode=MAAS-B5CE4483
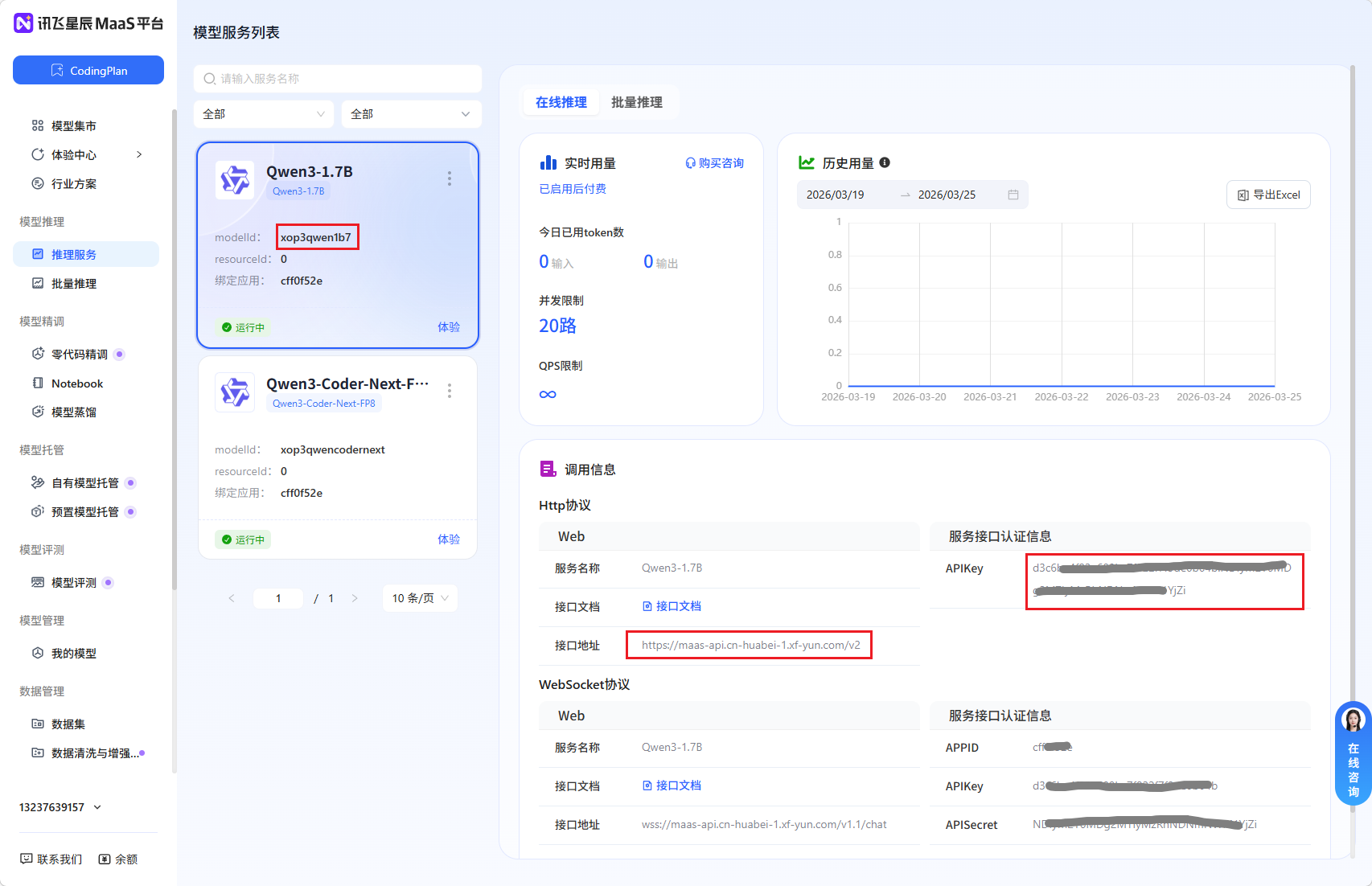
baseUrl:https://maas-api.cn-huabei-1.xf-yun.com/v2
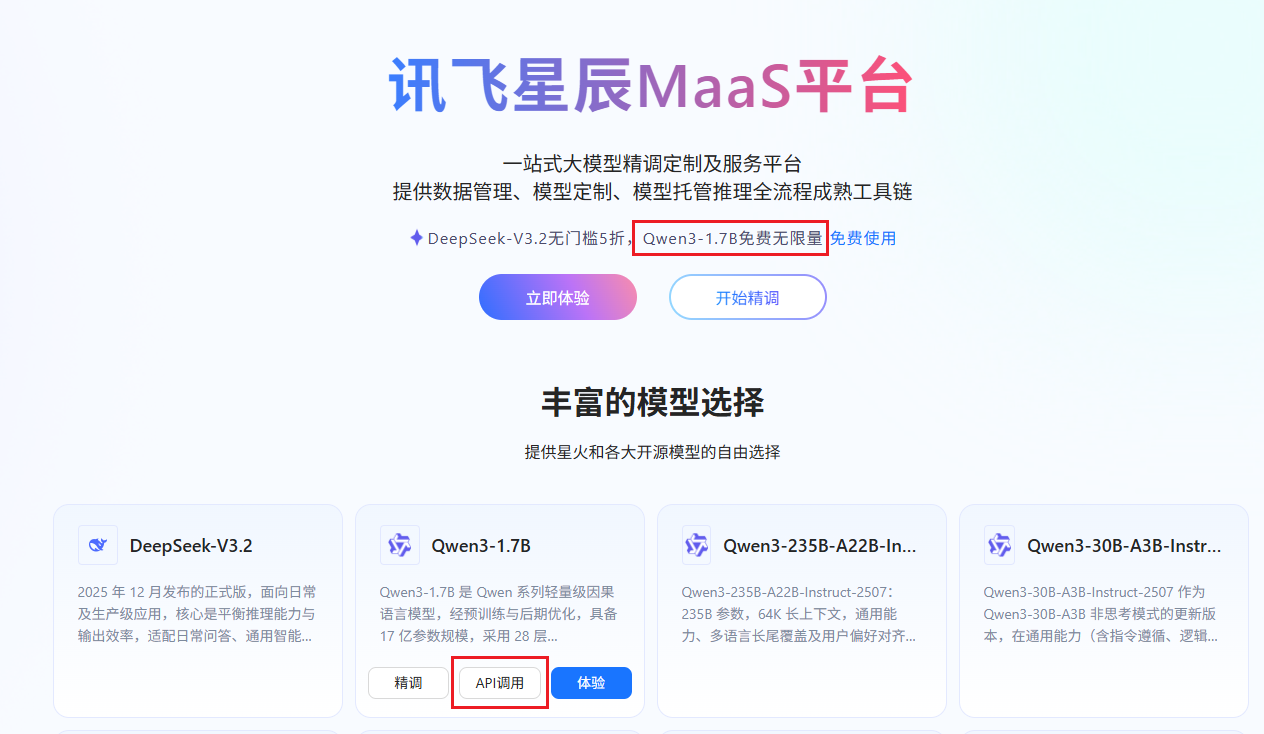
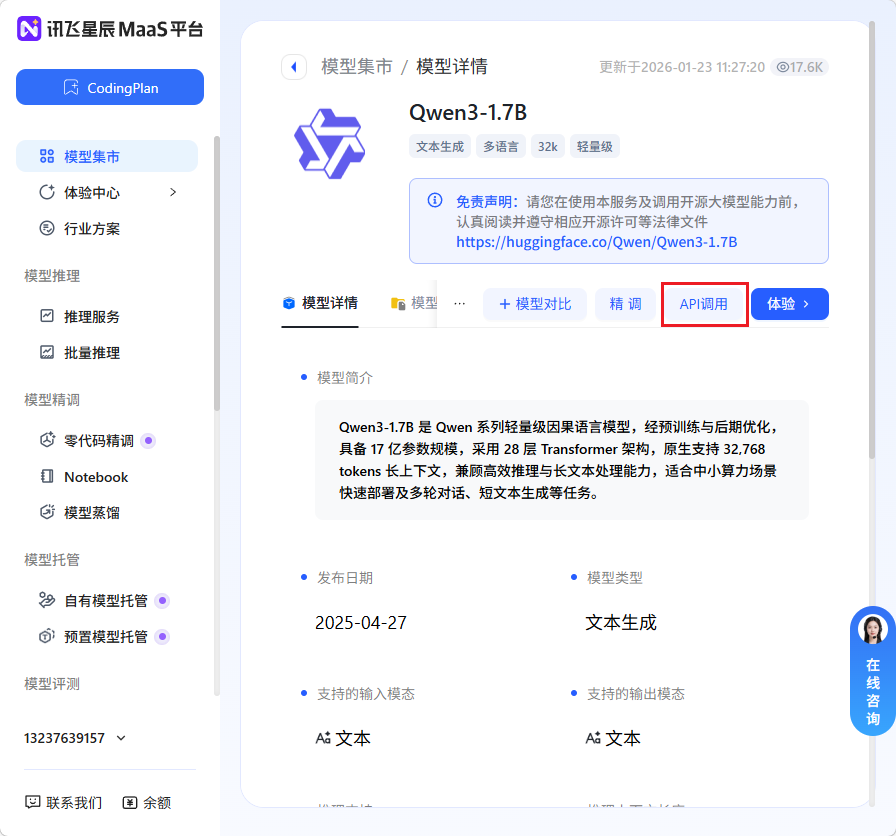
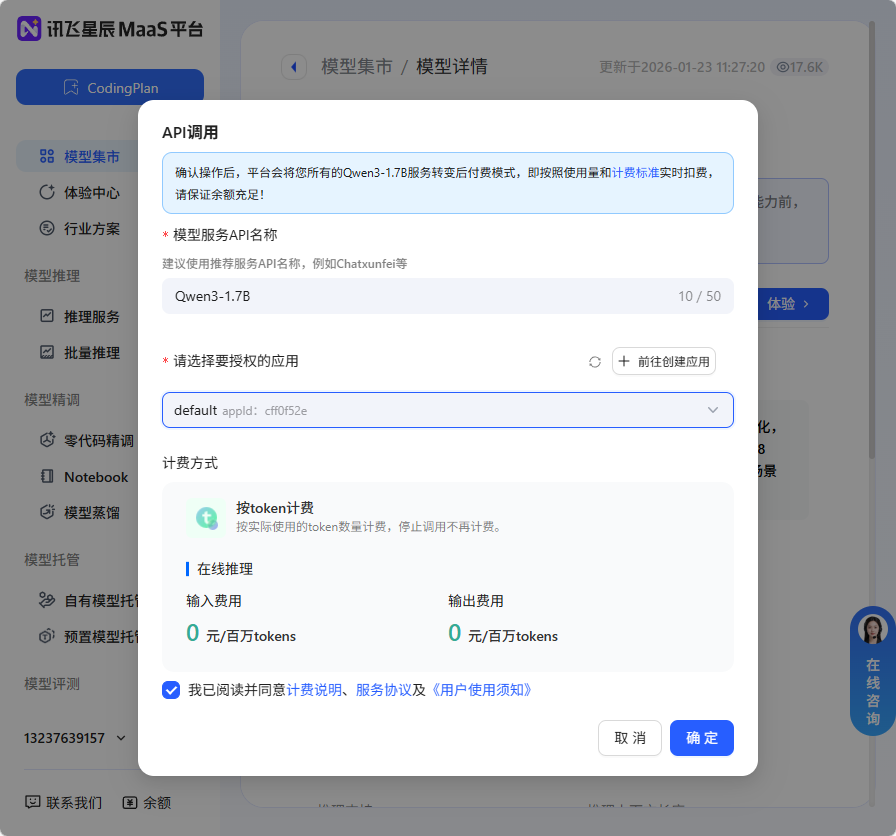
apiKey 怎么弄请看图:
申请入口:https://xinghuo.xfyun.cn/maas-home
可用模型列表:
| 模型id | 说明 | 最大输入 | 最大输出 | 最大思维链长度 | 上下文 | 请求限制 |
|---|---|---|---|---|---|---|
| Qwen3.5-35B-A3B | 千问3.5-35B-A3B(昵称:小橙鱼)是由阿里云通义千问团队推出的超大规模多模态语言模型,总参数35B、激活3B,采用稀疏MoE架构(256个专家,激活8个路由+1个共享)。原生支持256k上下文,可扩展至1M+;集成统一视觉-语言训练,在多语言(201种)、STEM推理、代码、视觉理解、视频分析及Agent任务等基准上达到顶尖水平,并具备工具调用与超长文本处理能力。 | 254k | 64k | 80k | 256k | QPS:20 |
| Qwen3-Coder-Next-FP8 | Qwen3-Coder-Next-FP8 系列模型(包括其更大版本如480B-A35B)的设计目标和公开评测结果均表明,其能力直接对标 Claude Sonnet 系列,尤其是在 Agentic Coding(智能体编程)、工具调用等任务上 ,它是专为编码代理(Coding Agent)和本地开发优化的专业模型,其核心优势在于代码生成、工具使用、长上下文处理和错误恢复等深度编码能力,而非通用的高阶复杂推理 | 200K | 64k | - | 256k | QPS:5 |
上方表格为什么没有 Qwen3-1.7B 和 Qwen3.5-2B,我测试发现 Qwen3-1.7B 和 Qwen3.5-2B 总是出bug,比如 timestamp 不存在,后来官方修好了,但是我不想用了,它们的上下文都只有32K,干不了什么。
而表格中的模型相对稳定,QPS限制也都很宽松。
附录:
模型请求限制术语:
| 限制术语 | 说明 |
|---|---|
| QPS | 每秒请求数 |
| QPM | 每分钟请求数 |
| QPD | 每天请求数 |
| RPM | 每分钟请求数 |
| TPM | 每分钟tokens数量 |
| RPD | 每天请求数 |
模型性能术语:
| 模型性能 | 说明 |
|---|---|
| TPOT(Time Per Token) | 每生成一个Token所需的时间,单位为毫秒 |
| TPS(Tokens Per Second) | 每秒生成的Token总数 |
二、开发不可用
1、魔塔社区
** 免费模型列表:https://www.modelscope.cn/models?filter=inference_type&page=1&sort=stars&tabKey=task**
** 每天2000次免费调用,需关联阿里云账号
实际测试魔塔社区也受全局限制:报了以下错误,但实际上请求之前至少10个小时没有进行过请求
响应内容: {
“error”: “ChatCompletionStream error: Post \“https://api-inference.modelscope.cn/v1/chat/completions\”: HTTP error: 429 Too Many Requests, body: {\“error\”:{\“code\”:\“1302\”,\“message\”:\“您的账户已达到速率限制,请您控制请求频率\”},\“request_id\”:\“a36b36b6-5c97-4be2-8072-6d0c5caaedac\”}”
}
2、opencode-zen
** 申请 API KEY :https://opencode.ai/zen
> 文档:https://opencode.ai/docs/zh-cn/zen/#for-teams
免费模型:https://blog.csdn.net/liuyunshengsir/article/details/158650643
实际测试 zen 的QPS是1:
响应内容: {
"error": "ChatCompletionStream error: Post \"https://opencode.ai/zen/v1/chat/completions\": HTTP error: 429 Too Many Requests, body: {\"type\":\"error\",\"error\":{\"type\":\"FreeUsageLimitError\",\"message\":\"Rate limit exceeded. Please try again later.\"}}"
}
3、七牛云
apiKey申请:https://portal.qiniu.com/ai-inference/api-key
用量看板:https://portal.qiniu.com/ai-inference/usage
控制台:https://portal.qiniu.com/home
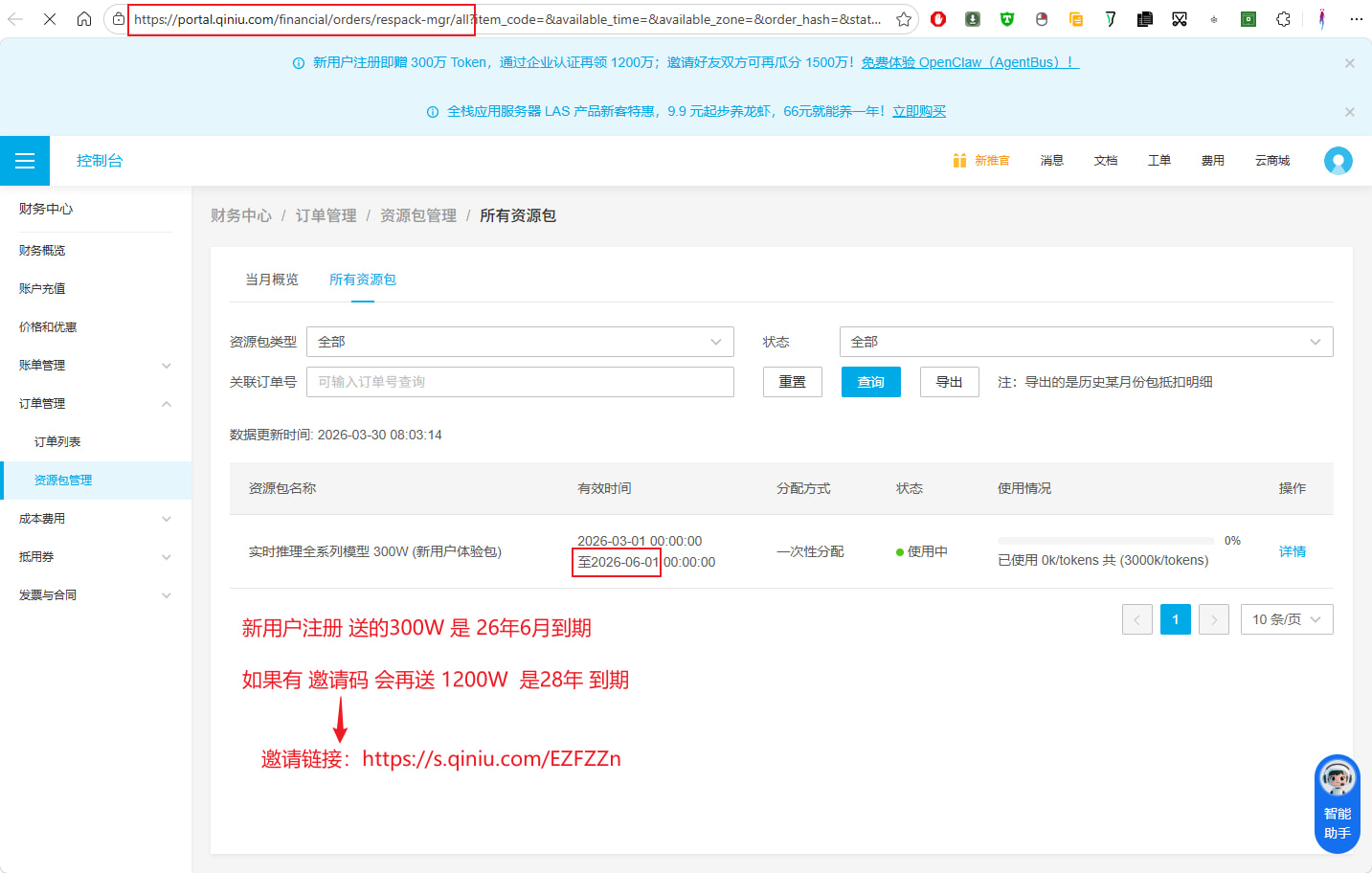
邀请链接:https://s.qiniu.com/EZFZZn(用这个链接送 1200W 资源包,可用付费模型,2年后过期)
提供两个免费模型:meituan/longcat-flash-lite 和 stepfun/step-3.5-flash
但!免费模型会出现上游错误:
响应内容: {
"error": {
"message": "Model resources are currently busy. Please try again later. (request_id: chatcmpl-be7e29b6f5094fabb3b4b4e370d96ffd)",
"type": "upstream_error"
}
}
4、智谱AI
邀请链接:https://www.bigmodel.cn/invite?icode=k0voaZBz1K26SzIwkPrTP%2Bnfet45IvM%2BqDogImfeLyI%3D
apiKey申请:https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
免费模型列表:https://docs.bigmodel.cn/cn/guide/models/free
模型速率限制:https://bigmodel.cn/usercenter/equity-mgmt/user-rights 及 https://bigmodel.cn/usercenter/proj-mgmt/rate-limits
baseUrl:https://open.bigmodel.cn/api/paas/v4
(实际测试它的体验地址:https://api.z.ai/api/paas/v4 比上方要快)
它的免费模型 官方文档上写的很清楚 QPS 有5的,还有10的,但是!智谱的免费模型限制还额外限于全局:
错误码:https://docs.bigmodel.cn/cn/faq/api-code
{
"error": {
"code": "1305",
"message": "该模型当前访问量过大,请您稍后再试"
}
}
及
{
"error": "ChatCompletionStream error: Post \"https://open.bigmodel.cn/api/paas/v4/chat/completions\": HTTP error: 429 Too Many Requests, body: {\"error\":{\"code\":\"1302\",\"message\":\"您的账户已达到速率限制,请您控制请求频率\"}}"
}
5、腾讯混元
当前仅提供1个免费模型:hunyuan-lite ,而且最新支持了 OpenAI 协议 调用
base_url:https://api.hunyuan.cloud.tencent.com/v1
apikey 申请: https://console.cloud.tencent.com/hunyuan/api-key
开发排除原因:太蠢!从2024年10月30号上架之后,腾讯就再也没管过,蠢得让人无法理喻!虽然有250K的上下文和最大6K的输出
6、讯飞星火
注意:这不是讯飞星辰
提供了1种免费模型:spark-lite,QPS为5,但上下文只有8k,最新支持了 OpenAI 协议 调用
开发排除原因:上下文容量太少
7、cloudflare
官网:https://developers.cloudflare.com/ 或 https://dash.cloudflare.com/
文档:https://developers.cloudflare.com/workers-ai/configuration/open-ai-compatibility/
速率限制:https://developers.cloudflare.com/workers-ai/platform/limits/
仪表盘:https://dash.cloudflare.com/{account_id}/ai/workers-ai/usage
baseUrl:https://api.cloudflare.com/client/v4/accounts/{account_id}/ai/v1
开发排除原因:每天10000个神经元,发个“你好”占用400神经元
8、github ai
apiKey申请:https://github.com/settings/personal-access-tokens
免费限制:15 RPM / 150 RPD
Diss掉的原因:RPM =15 :每分钟请求15次,实际QPS≈…?
9、AtomGit AI
gitcode 出品 ,无限量(每24小时续一次命)
续命地址:https://ai.gitcode.com/serverless-api
baseUrl:https://api.gitcode.com/api/v5
可用模型列表:https://ai.gitcode.com/models?exp=ONLINE
用量看板:https://ai.gitcode.com/dashboard/free-token
开发排除原因:QPM=10:实际QPS≈0.17,而且每24小时需要续命一次:

10、NVIDIA
短信验证时不要选择地区,把 +1 改成 +86 后面跟手机号即可
模型列表:https://build.nvidia.com/models?orderBy=name%3AASC&filters=nimType%3Anim_type_preview
apiKey 申请:https://build.nvidia.com/settings/api-keys
baseUrl:https://integrate.api.nvidia.com/v1
Diss掉的原因:巨慢,慢到超时(偶尔会响应)
11、huggingface
被墙可用 https://www.dogfight360.com/blog/18682/ 的Steamcommunity_302进行加速
模型列表:https://huggingface.co/models?inference_provider=all&sort=trending
创建apiKey:https://huggingface.co/settings/tokens
base_url:https://router.huggingface.co/v1
开发排除原因:巨慢,慢到超时(偶尔会响应),怀疑是不是NVIDIA的中转站
12、火山方舟
火山方舟是火山引擎推出的大模型服务平台,开局每个模型赠送50W
开启 协作奖励计划 后 会要求关闭 安心体验 且无法再开启,但每日赚送 250W tokens(仅能指定1个模型)
控制台:https://console.volcengine.com/ark/region:ark+cn-beijing/openManagement
免费资源余量看板:https://console.volcengine.com/finance/resource-package
用量看板:https://console.volcengine.com/ark/region:ark+cn-beijing/usageTracking
密钥创建:https://console.volcengine.com/iam/keymanage
baseUrl:https://ark.cn-beijing.volces.com/api/v3/
开发排除原因:提供商想要我们的数据训练模型,又不想给太多,250W 跑5个小任务就没了
三、可用于开发:3家限量模型-千万起步
1、七牛云 - 有效期 2个月
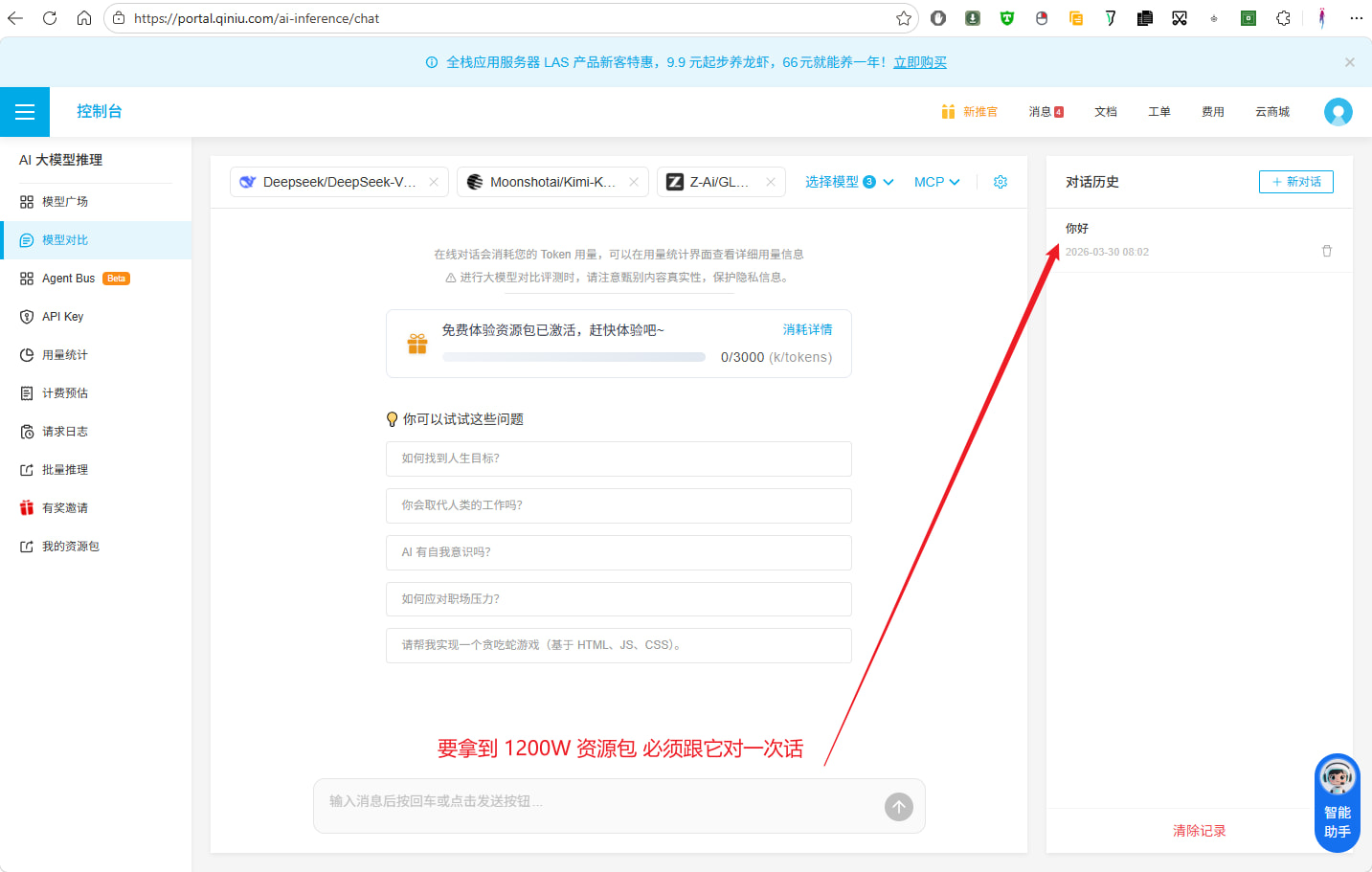
新用户注册 送 300W tokens 资源包,全系列免费用,觉得 300W 太少?用我这个邀请链接: https://s.qiniu.com/EZFZZn 会送 1200W tokens 资源包
要拿到这1200W 你要实名注册,并且有个坑点,你必须跟 https://portal.qiniu.com/ai-inference/chat 它对一次话。
baseUrl:https://api.qnaigc.com/v1
apiKey申请:https://portal.qiniu.com/ai-inference/api-key
用量看板:https://portal.qiniu.com/ai-inference/usage
控制台:https://portal.qiniu.com/home
模型列表:https://portal.qiniu.com/ai-inference/model 或 https://www.qiniu.com/ai/models
七牛云 开发推荐用的模型:
| 模型id | 模型别名 | 说明 | 最大输入 | 最大输出 | 最大思维链长度 | 上下文 | 类型 | 请求限制 |
|---|---|---|---|---|---|---|---|---|
| z-ai/glm-5 | glm-5 | GLM-5 是智谱新一代的旗舰基座模型,面向 Agentic Engineering 打造,能够在复杂系统工程与长程 Agent 任务中提供可靠生产力。在 Coding 与 Agent 能力上,GLM-5 取得开源 SOTA 表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务,是通用 Agent 助手的理想基座。 | 116k | 16k | - | 198k | 文本 | 1000次调用 /5小时 |
| z-ai/glm-4.7 | glm-4.7 | GLM-4.7 是智谱最新旗舰模型,面向 Agentic Coding 场景强化了编码能力、长程任务规划与工具协同,并在多个公开基准的当期榜单中取得开源模型中的领先表现。通用能力提升,回复更简洁自然,写作更具沉浸感。在执行复杂智能体任务,在工具调用时指令遵循更强,Artifacts 与 Agentic Coding 的前端美感和长程任务完成效率进一步提升 | 116k | 16k | - | 198k | 文本 | 1000次调用 /5小时 |
| moonshotai/kimi-k2.5 | kimi-k2.5 | Kimi K2.5 是 Kimi 迄今最智能的模型,在 Agent、代码、视觉理解及一系列通用智能任务上取得开源 SoTA 表现。同时 Kimi K2.5 也是 Kimi 迄今最全能的模型,原生的多模态架构设计,同时支持视觉与文本输入、思考与非思考模式、对话与 Agent 任务。 | 224k | 16k | - | 256k | 多模态 | 1000次调用 /5小时 |
| minimax/minimax-m2.5 | minimax-m2.5 | Minimax M2.5专为Agent场景原生设计,编程与智能体性能(Coding & Agentic)直接对标Claude Opus 4.6,尤其在Excel高阶处理、PPT生成和深度调研等Office生产力场景达到行业领先水平(SOTA)。 | 192k | 128k | - | 200k | 文本 | 1000次调用 /5小时 |
| qwen3-coder-480b-a35b-instruct | qwen3-coder-480b-a35b-instruct | Qwen3-Coder-480B-A35B-Instruct是由Qwen团队开发的混合专家(MoE)代码生成模型。该模型专为智能编码任务优化,涵盖函数调用、工具使用及代码库长上下文推理等场景。其总参数量达4800亿,每次前向传播激活350亿参数(动态激活160个专家中的8个) | 200k | 64k | - | 256k | 文本 | 1000次调用 /5小时 |
| qwen/qwen3.6-plus-free | qwen3.6-plus | 建立在混合架构之上,结合了高效的线性注意力与稀疏专家混合路由,实现了强大的可扩展性和高性能推理。与3.5系列相比,它在代理编码、前端开发以及整体推理方面取得了重大进步,显著提升了“氛围编码”体验。该模型在复杂任务如3D场景、游戏和仓库级问题解决方面表现出色,在SWE-bench Verified上取得了78.8分。它在纯文本和多模态能力方面实现了重大飞跃,表现达到了最先进模型的水平。 | - | 66k | - | 1m | 文本,视觉 | 1000次调用 /5小时 |
| qwen/qwen3.6-plus-preview | qwen3.6-plus | 用了先进的混合架构,在效率与可扩展性上均有提升。与 3.5 系列相比,它具有更强的推理能力和更可靠的智能体行为表现。在基准测试中,其性能达到或超越当前领先的业界顶尖模型。作为旗舰级预览版本,它在智能体编程、前端开发及复杂问题求解方面表现尤为出色。 | - | 66k | - | 1m | 文本,视觉 | 1000次调用 /5小时 |
| qwen3-max | qwen3-max | 本版本相较preview版本在智能体编程与工具调用方向进行了专项升级。本次发布的正式版模型达到领域SOTA水平,适配场景更加复杂的智能体需求 Preview 版本相较 2.5 系列整体通用能力有大幅度提升。参数量达 1T,大幅减少知识幻觉,模型更智能。 | 252k | 64k | 80k | 256k | 文本 | 1000次调用 /5小时 |
| doubao-seed-2.0-pro | doubao-seed-2.0-pro | 旗舰级全能通用模型,面向 Agent 时代的复杂推理与长链路任务执行场景。强调多模态理解、长上下文推理、结构化生成与工具增强执行。复杂指令与多约束执行能力突出,可稳定应对多步复杂规划、复杂图文推理、视频内容理解与高难度分析等场景 | - | 128k | - | 256K | 文本,视觉 | 1000次调用 /5小时 |
| doubao-seed-2.0-code | doubao-seed-2.0-code | 面向真实编程环境优化的 Coding 模型,能稳定调用 Claude Code 等常见 IDE 中的工具。模型特别优化了前端能力,在使用常见的前端框架时能有良好表现。模型支持使用 Skills,可以配合多种自定义技能使用。 | - | 128k | - | 256K | 文本,视觉 | 1000次调用 /5小时 |
| deepseek/deepseek-v3.1-terminus | deepseek-v3.1 | 此次更新在保持模型原有能力的基础上,针对用户反馈的问题进行了改进,包括: 语言一致性:缓解了中英文混杂、偶发异常字符等情况; Agent 能力:进一步优化了 Code Agent 与 Search Agent 的表现。(非思考) | - | 32k | - | 128k | 文本 | 1000次调用 /5小时 |
| deepseek/deepseek-v3.2-251201 | deepseek-v3.2 | 此次更新强化了 Agent 和推理能力,在主流测试中达到 GPT-5 水平并支持思考模式下的工具调用;同时推出的 Speciale 探索版在多项国际竞赛中取得金牌级表现。模型已全面开放使用。(思考) | - | 64k | - | 128k | 文本 | 1000次调用 /5小时 |
看你的资源包是否到账:
https://portal.qiniu.com/financial/orders/respack-mgr/all
Snipaste_2026-04-04_00-56-111433×912 188 KB
Snipaste_2026-04-04_00-48-371433×911 151 KB
2、智谱AI - 有效期 3个月
使用这个链接赠送 1200W glm-4.5-air 和 600W glm-6v:非常适合用于网页分析任务
https://www.bigmodel.cn/invite?icode=k0voaZBz1K26SzIwkPrTP%2Bnfet45IvM%2BqDogImfeLyI%3D
(右上角 -财务-资源包 点击查看是否到账)
免费模型列表:https://docs.bigmodel.cn/cn/guide/models/free
模型速率限制:https://bigmodel.cn/usercenter/equity-mgmt/user-rights 及 https://bigmodel.cn/usercenter/proj-mgmt/rate-limits
用量看板:https://bigmodel.cn/usercenter/glm-coding/usage
baseUrl:https://open.bigmodel.cn/api/paas/v4
apiKey申请:https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
| 模型id | 说明 | 最大输入 | 最大输出 | 上下文 | 最大思维链长度 | 类型 | 请求限制 | 限量 |
|---|---|---|---|---|---|---|---|---|
| glm-4.5-air | GLM 系列中的一个中等规模模型,采用 混合专家架构(Mixture of Experts, MoE),相比 GLM-4.5,GLM-4.5-Air 的参数规模更为紧凑(总参数为 1060 亿,激活参数为 120 亿)。适用领域:网页浏览:借助网页浏览工具,可以处理包含多轮交互、多步骤任务的复杂网页浏览场景。智能体编程:支持在智能体环境下执行编程任务,如开发小游戏、创建交互式网页等。在 推理任务 中,GLM-4.5-Air 表现出优异的性能。它支持多种推理方式(如 MTP 技术)以及多轮对话理解,在多个基准测试中都能稳定输出高质量结果。擅长基于代码和推理任务的多模态处理,并支持通过工具调用接口实现一系列智能体功能。例如,它可以基于提示在前端开发一个完整的网页项目,包括布局、交互、播放等处理。 | 96k | 16k | - | 128k | 文本 | QPS:5 | 2400W |
| glm-4.6v | 面向视觉-语言任务的新迭代多模态大模型系列,相对 GLM-4.5V 进行了全面升级。官方介绍显示,该系列在训练阶段将上下文规模扩展至 128K,并首次引入原生的 Function Calling,用于跨“视觉感知”与“可执行动作”的闭环,多用于真实业务场景中的多模态 Agent | - | - | 128k | - | 多模态 | QPS:10 | 1200W |
3、国家超算平台 - 有效期 15天
注册赠送:1000W 的MinMax 2.5,和 1000W 通用资源包 (活动时间截止 2026-04-06)
baseUrl:https://api.scnet.cn/api/llm/v1/
模型列表:https://www.scnet.cn/ui/llm/
友情提醒:可以用多个手机号注册多个账号(多倍快乐)
| 模型id | 说明 | 最大输入 | 最大输出 | 最大思维链长度 | 上下文 | 类型 |
|---|---|---|---|---|---|---|
| MiniMax-M2.5 | 原生 Spec 能力(在编码前自动拆解需求,生成架构图与功能模块规划,接近人类架构师思维) 工具调用增强,多编程语言支持(代码生成质量接近生产级) 编程效率 对标 GPT-4 Turbo | 192k | 128k | - | 200k | 文本 |
| Qwen3-235B-A22B-Thinking-2507 | Qwen3-235B-A22B-Thinking-2507是一个超大规模语言模型,总参数量为2350亿,激活参数量为220亿。它改进了推理能力和大规模文本生成能力,特别适用于需要深入推理的复杂任务。该模型强化了推理、代码和智能体任务的性能,并且在多个学术与实战基准测试中表现卓越。此外,该模型现今支持最大长度为262,144 tokens的上下文,并且通过Dual Chunk Attention (DCA) 和 MInference 技术实现更高效地处理超长文本。 | 124k | 32k | 80k | 128k | 文本 |
| Qwen3-235B-A22B | Qwen3-235B-A22B 是一个稠密与混合专家(MoE)模型的综合,并在推理、指令跟随、代理能力及多语言支持方面取得了突破性进展。模型总参数量为 2350亿,激活参数为 220亿。支持复杂逻辑推理、数学、编程等任务的推理模式,以及通用对话的非推理模式,并具备在 131,072 个 tokens 的上下文中进行推理的潜力。 | 126k | 16k | 38k | 128k | 文本 |
| Qwen3-30B-A3B-Instruct-2507 | Qwen3-30B-A3B-Instruct-2507具有30.5B的总参数量和3.3B的激活参数量,训练数据达到28.5T tokens。它只支持非思考模式,在推理、代码和智能体任务中表现优异,并且在多项学术与实战基准测试中达到世界领先的开源模型水准,接近前沿闭源模型。模型原生支持262,144个token的上下文,具有显著提升的长上下文理解能力。同时,它采用了Dual Chunk Attention(DCA)技术和MInference技术,能够在1M token上下文中实现高效推理,并在接近1M token时达到标准注意力实现的3倍速度提升。 | 126k | 32k | - | 256k | 文本 |
| Qwen3-30B-A3B | Qwen3-30B-A3B 推理能力以更小参数规模比肩QwQ-32B,支持推理、指令遵循、智能体等多个功能,参数量达30.5B(激活3.3B),通用能力显著超过Qwen2.5-14B,达到同规模业界SOTA水平 | 96k | 8k | - | 128k | 文本 |
| QwQ-32B | 基于Qwen2.5-32B基座,大幅度提升了模型推理能力。模型数学代码等核心指标(AIME 24/25、livecodebench)以及部分通用指标(IFEval、LiveBench等)达到DeepSeek-R1 满血版水平,各指标均显著超过 DeepSeek-R1-Distill-Qwen-32B | 96k | 8k | - | 128k | 文本 |
| DeepSeek-R1-Distill-Llama-70B | 基于 Llama-70B 通过 DeepSeek-R1 知识蒸馏训练的70B参数量推理模型,专为推理和思维链任务优化,在数学推理(AIME 2024: 70.0% pass@1, MATH-500: 94.5% pass@1)和代码生成(CodeForces: 1633, 57.5% pass@1)方面表现出色,代码优化任务佳,运行效率提升 12%。在复杂逻辑推理、数学与代码理解等任务上具备强大性能,适合对效果与稳定性要求极高的高端生产与科研场景。 | - | - | - | 128k | 文本 |