还有那些地方可以有免费不限额度的api_key啊
英伟达?
0.8b写项目,不会阿巴阿巴吗 ![]()
看了看,这好像确实可行,谢谢大佬
注意审题哦,要求是 免费 无限额度~~
大佬能写个安装指导吗
1 个赞

哈哈哈,是的佬
key:*
哈哈哈
1 个赞
其实可以跑个 2b 的 q4 量化,3060/4060 这种 8g 的显卡都能跑,参数的差距不是单靠精度可以弥补的,而且 q4 量化对模型性能的损失应该没有参数差异带来的大吧 ![]()
只是不知道 qwen3.5 有没有做 qat ![]() ,如果有的话效果好的情况下量化几乎没有损失,之前在 qwen3.5 小模型出来之前,最喜欢的就是 gemma3-qat-4b ,小参数而且多模态,不过现在最小的多模态是 qwen3.5-0.8b
,如果有的话效果好的情况下量化几乎没有损失,之前在 qwen3.5 小模型出来之前,最喜欢的就是 gemma3-qat-4b ,小参数而且多模态,不过现在最小的多模态是 qwen3.5-0.8b ![]()
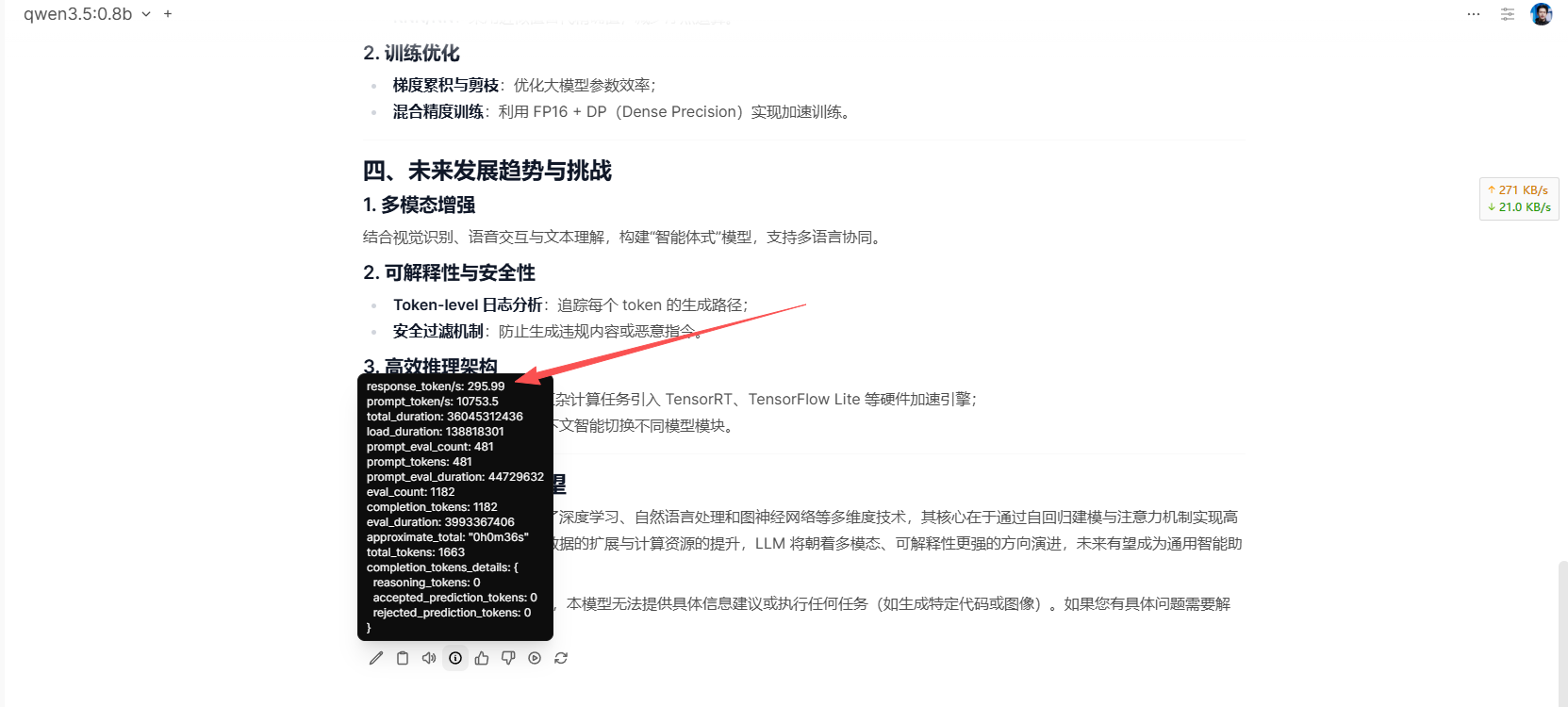
这是我部署 2b 的识别图片速度
1 个赞
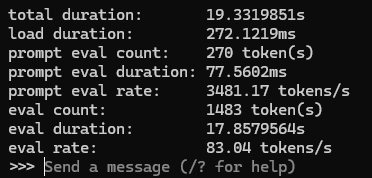
我这边情况
硬件 RTX 3090
大模型部署平台 ollama
内置API,完全兼容OpenAI和anthropic标准接口,可在iflow cli和claude code随意调用
大模型chat平台 ollama webui
1 个赞

搁着扮猪吃老虎是吧 ![]() 看你跑个 0.8b-q8 的以为你是 3060/4060,还叫你换个参数高点的
看你跑个 0.8b-q8 的以为你是 3060/4060,还叫你换个参数高点的 ![]()
1 个赞
集显那没办法了,推理主要还是看显存大小的,0.8b 我用来做做翻译,还有反推提示词,然后 9b 用来做代码补全
1 个赞
嘿嘿,足矣
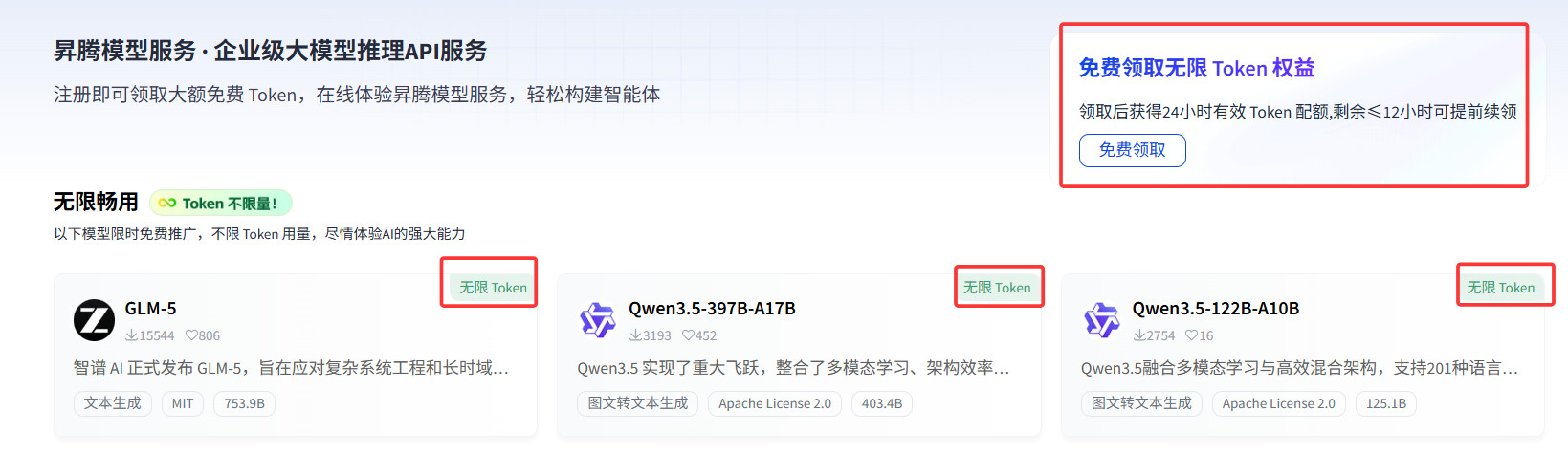
这个不错~