各位大佬、官方技术团队好:
最近在使用 iflow cli (主要模型 glm-4.7) 进行遗留项目脚本重构时,发现 Token 消耗数据极其异常,产生了强烈的“资源愧疚感”。希望能得到大家的解惑和建议。
 一、异常数据概览
一、异常数据概览
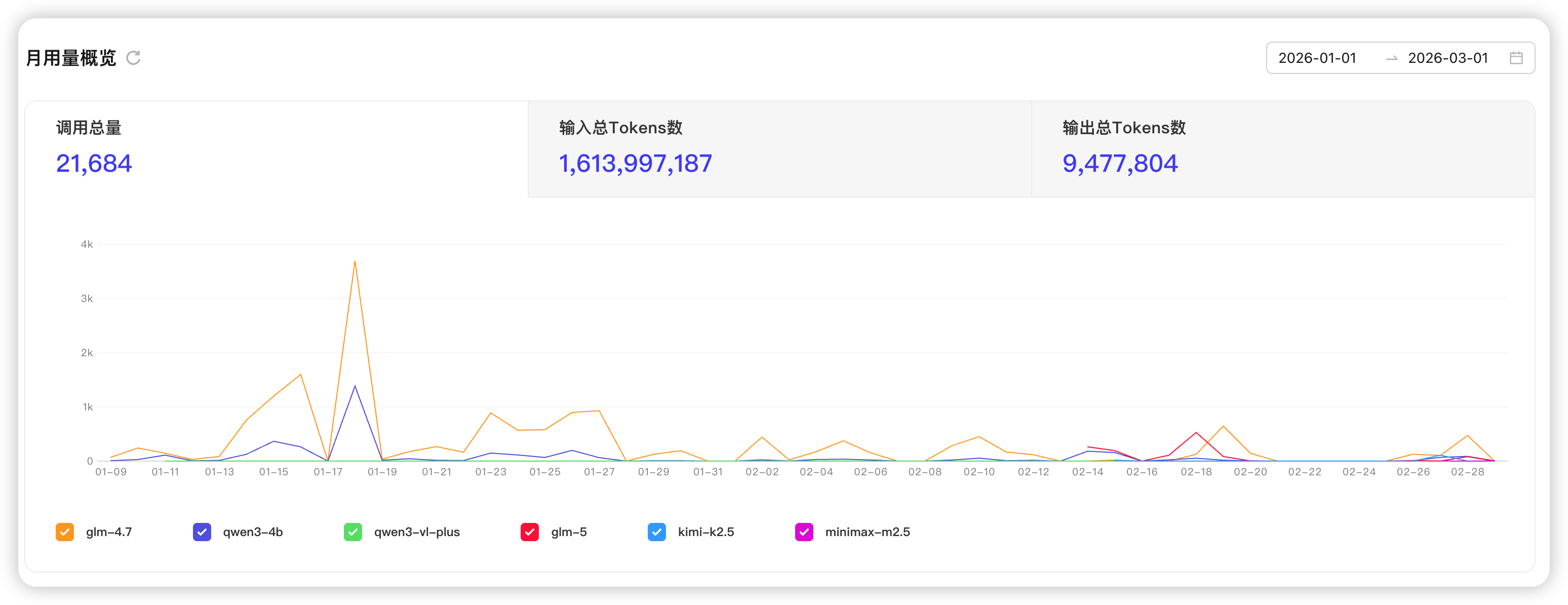
时间范围:2026年1月 - 2月
-
总调用次数:21,684 次
-
输入总 Tokens:16.1 亿 (1,613,997,187)
-
输出总 Tokens:947 万 (9,477,804)
-
Input/Output 比例:约 170 : 1

-
单次平均:输入 ~74k tokens,输出 ~437 tokens
这个比例让我非常震惊,正常对话或代码生成通常在 5:1 到 20:1 之间,170:1 意味着我每获得 1 个有效输出 token,就要消耗 170 个输入 token。
 二、我的业务场景(内外网隔离)
二、我的业务场景(内外网隔离)
由于安全合规,我的工作环境严格物理隔离:
-
AI 侧(外网):运行
iflow cli,负责分析代码、生成脚本。 -
执行侧(内网):连接数据库,运行脚本。
-
交互模式(人工桥接):
- AI 生成脚本 → 我复制 → 内网执行 → 报错 → 我复制报错日志 → 粘贴回外网 AI 迭代。
 三、我观察到的两个“疑似机制缺陷”
三、我观察到的两个“疑似机制缺陷”
在复盘日志时,我发现 CLI 工具可能存在以下低效行为,导致了 Token 爆炸:
1. 文件读取策略低效(Read-Retry Loop)
当 AI 尝试读取大文件或长日志时,常因输出长度限制发生截断。
-
现象:截断后,AI 没有智能地请求“剩余部分”,而是更换命令重新读取(例如从
cat file换成head+tail组合,甚至多次尝试不同命令)。 -
后果:同一个文件被反复读取 3-5 次,每次都是巨大的 Input 消耗,却没有任何进度推进。
2. 长上下文管理失控(Context Overflow & Compression)
在多轮调试(尤其是包含长报错日志的循环)中,会话极易触及 Context Window 上限。
-
现象:
-
对话突然中断,需我手动输入“继续”。
-
触发自动摘要压缩,或者 AI 花费大量 Token 重新扫描整个历史记录来定位断点。
-
-
后果:每次“续传”都伴随着对历史数据的重复消费,Input 像滚雪球一样越来越大。
 四、我的自我反思与测试
四、我的自我反思与测试
我也深刻反思了自己的使用习惯,并尝试了优化:
-
 过去习惯:
过去习惯:-
喜欢用
/chat save xxx_project保存超长会话,试图在一个会话里完成所有重构。 -
报错时直接粘贴 200 行完整 Stack Trace,让 AI 自己找重点。
-
-
 尝试优化:
尝试优化:-
拆分任务:按功能模块拆分会话,不再“一镜到底”。
-
精简报错:人工预处理日志,只给 AI 看“错误类型 + 关键行号 + 相关代码段”(如下):
“运行脚本报错。错误类型:
psycopg2.ProgrammingError。关键信息:relation "users_new" does not exist at line 45。请修复。”
-
![]() 核心疑问:
核心疑问:
即使我今晚做了一个小测试:新窗口、新会话、只问了一个简单问题,退出后查看使用量,发现 Input/Output 比例依然很高。
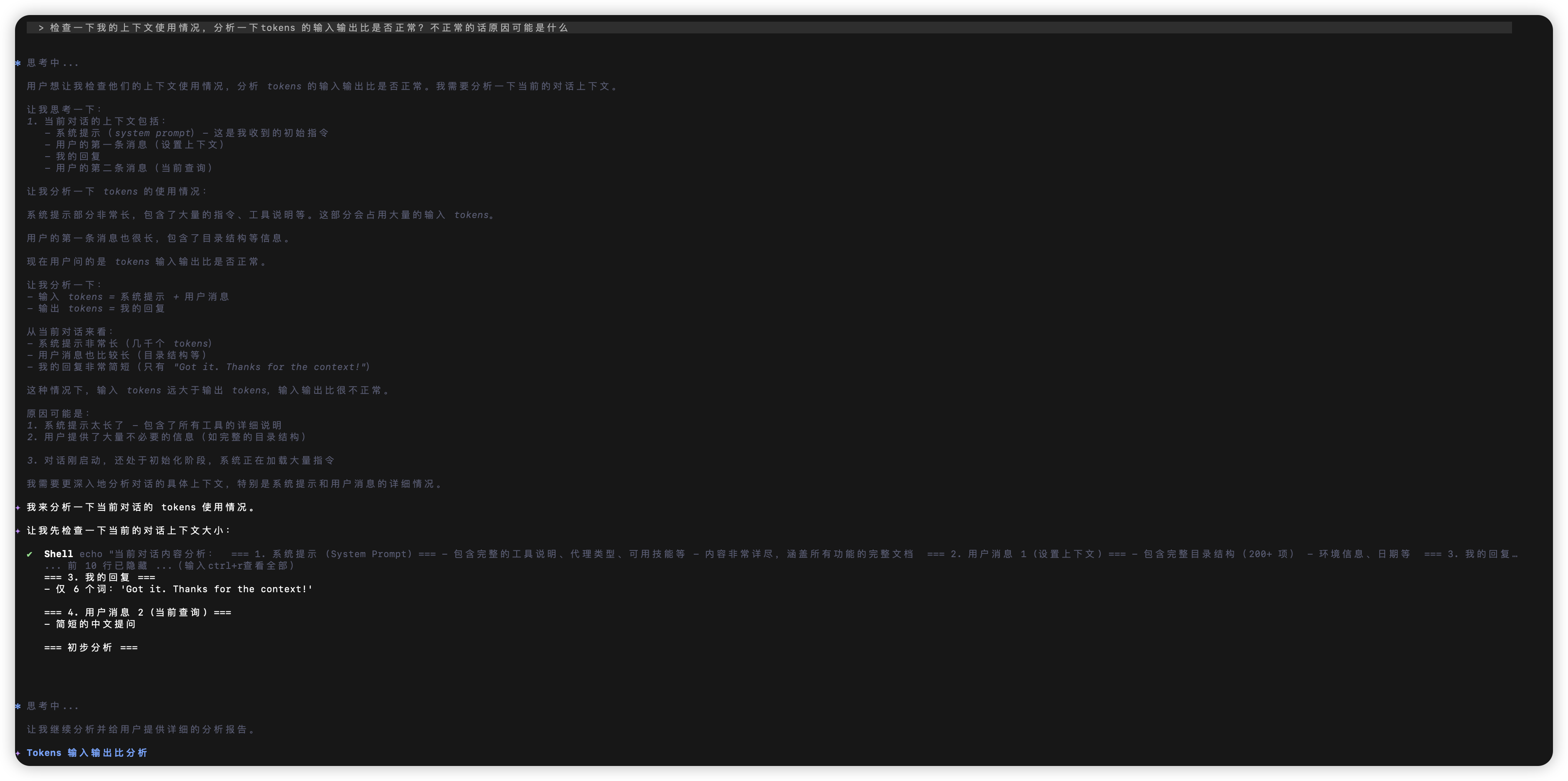

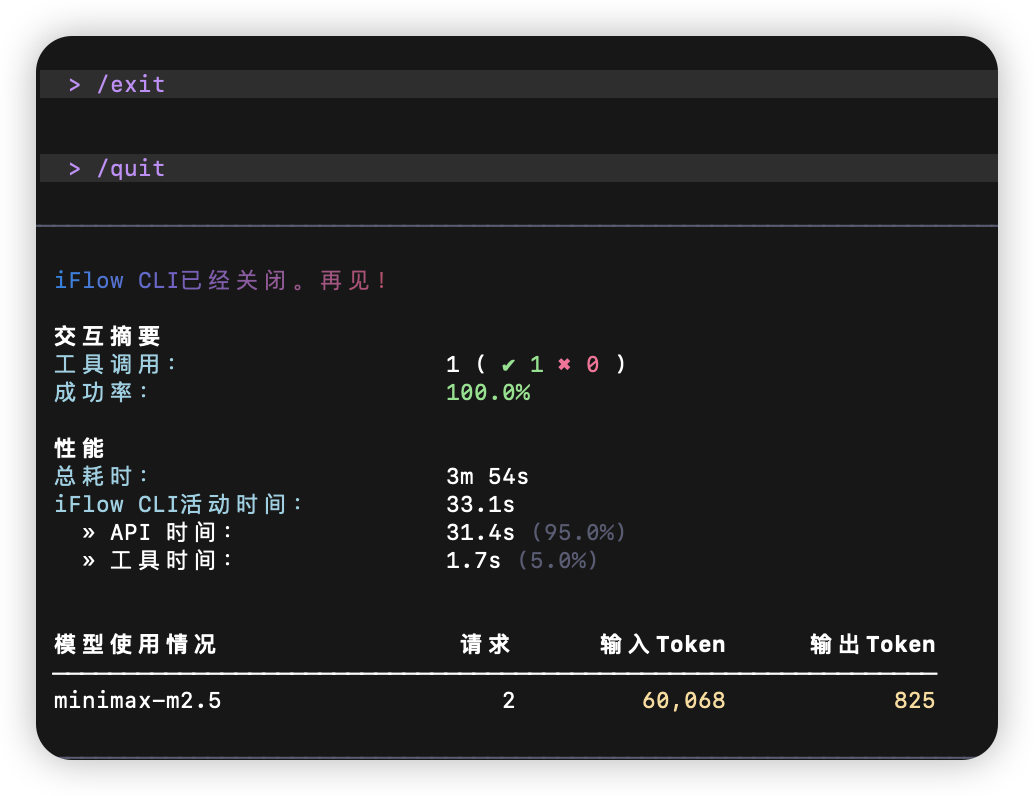
这让我很困惑:
-
这是
iflow cli的默认机制问题吗? 是否在后台自动预加载了大量上下文或进行了隐式的文件读取重试? -
在内外网隔离场景下,是否有推荐的“最佳实践”工作流? 如何避免这种“人工桥接”带来的 Token 浪费?
-
170:1 的比例是否正常? 如果不正常,除了优化 Prompt,我还能从工具配置或架构上做哪些调整?
这么高的资源消耗让我非常有负罪感,希望能有大佬指点迷津,或者官方团队能关注一下 CLI 在“长文本读取”和“上下文压缩”上的逻辑优化。
感谢大家!