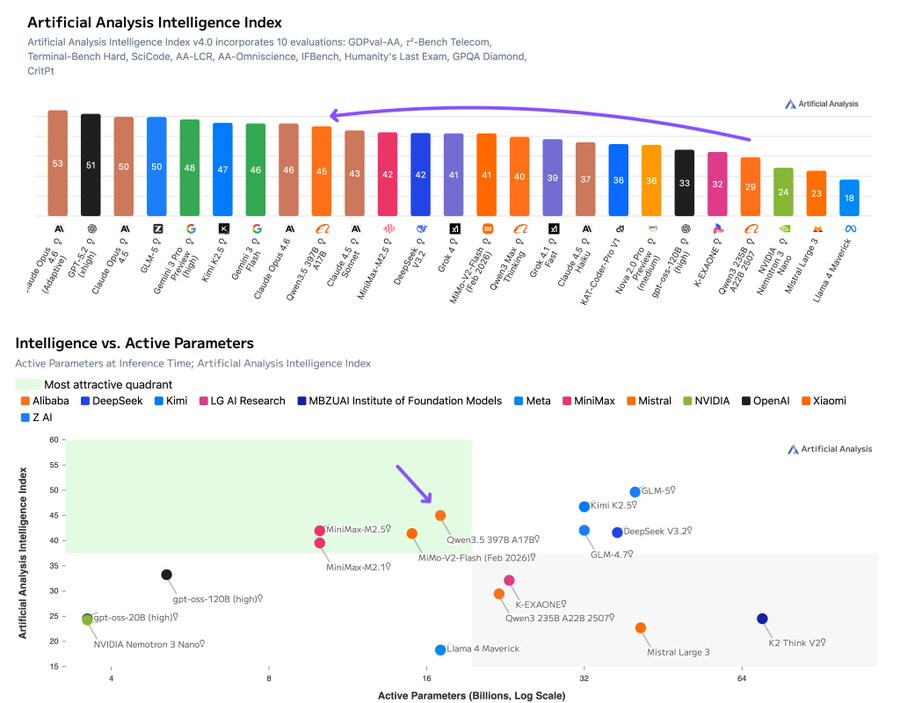
与其听厂商自吹,不如看独立评测机构 Artificial Analysis 对最新发布的 Qwen3.5-397B-A17B 的完整深度测评。相比上一代 Qwen3-235B,这次的升级方案在活跃参数更低的情况下实现了性能的飞跃,但同时也揭示了一些不容忽视的短板。
 核心评测数据 (Intelligence Index #3)
核心评测数据 (Intelligence Index #3)
Qwen3.5 最大的惊喜在于极致的“以小博大”——总参数量 397B,但活跃参数仅为 17B。这一数字显著低于 Kimi K2.5 (32B)、GLM-5 (40B) 和 DeepSeek V3.2 (37B)。
- 智力指数 (Intelligence Index):得分 45(较前代 Qwen3-235B 的 29 分大幅跃升)。
- 开源排名:位列开源模型 第 3 名,仅次于 GLM-5 (50分) 和 Kimi K2.5 (47分)。
- ELO 质量分:GDPval-AA ELO 达到 1,221,较前代暴涨了 361 分。该指标主要衡量模型在真实知识工作(演示稿制作、分析等)中的表现。
 技术演进:由“繁”入“简”
技术演进:由“繁”入“简”
- 母体统一(Native Vision):这是 Qwen 首个原生支持图像和视频输入的开源模型。此前,通义千问需要区分 VL 版和纯文本版,从 3.5 开始正式合二为一,紧跟行业原生多模态趋势。
- 模式融合:不再发布独立的“Instruct”和“Thinking”变体。Qwen3.5 在单个模型中通过不同触发方式支持推理(Reasoning)和非推理模式,极大降低了 Agent 部署的复杂性。
 绕不开的短板:幻觉率依然居高
绕不开的短板:幻觉率依然居高
这是本次测评中最值得关注的一点:
- 全知指数 (AA-Omniscience Index):得分 -32。虽然比前代的 -48 有所进步,但依然远逊于 Kimi K2.5 (-11) 和 GLM-5 (-1)。
- 幻觉率:数据为 88%(前代为 90%)。分数的提升主要靠准确率(Accuracy 30% vs 22%)撑起,而在“不懂就说不懂”的拒绝能力上,进步微乎其微。
 Token 效率与规格
Token 效率与规格
- Token 消耗:在运行智力测试时使用了约 86M 输出 Token(其中 80M 为推理 Token),虽多于前代,但少于 Kimi (89M) 和 GLM-5 (110M),体现了较强的 Token 效率。
- 上下文窗口:权重版为 262K;通过阿里云百炼提供的托管版 Qwen3.5-Plus 可支持 1M 窗口及内置工具调用(Tool Use)。
- 开源协议:Apache 2.0,对开发者非常友好。
 深度观点
深度观点
Qwen3.5-397B 证明了 17B 激活量就能跑出准一流性能。它是一个效率极高的“小钢炮”,但在应对高难度知识问答时的“自信幻觉”风险依然存在。
建议:在需要复杂 Agent 编排的任务中,它的成本优势无可比拟;但在对事实准确性要求极高的场景下,仍需配合 RLF 方案或参考 Kimi/GLM。