通义千问团队今日正式发布了 Qwen3.5 系列大模型。这次的更新堪称“效率革命”,在保持超强性能的同时,极大地优化了推理成本和多模态原生能力。
 核心架构突破:线性注意力 + Sparse MoE
核心架构突破:线性注意力 + Sparse MoE
Qwen3.5 采用了一套极具开创性的混合架构:线性注意力机制(Gated Delta Networks) 结合 局部稀疏混合专家(Sparse MoE)。
- 参数量:总参数量高达 397B,但每次推理仅激活 17B。
- 性能怪兽:以 17B 的激活参数实现了超越 1T 等级模型的水平。
 关键特性
关键特性
- 原生多模态 (Native Multimodal):并非单纯的插件式升级,而是从基础层就支持原生视觉-语言理解。
- 超长上下文 (1M Context):API 版本支持高达 100 万 token 的长文本处理。
- 全球化升级:支持语言从 119 种扩展至 201 种 语言及方言。
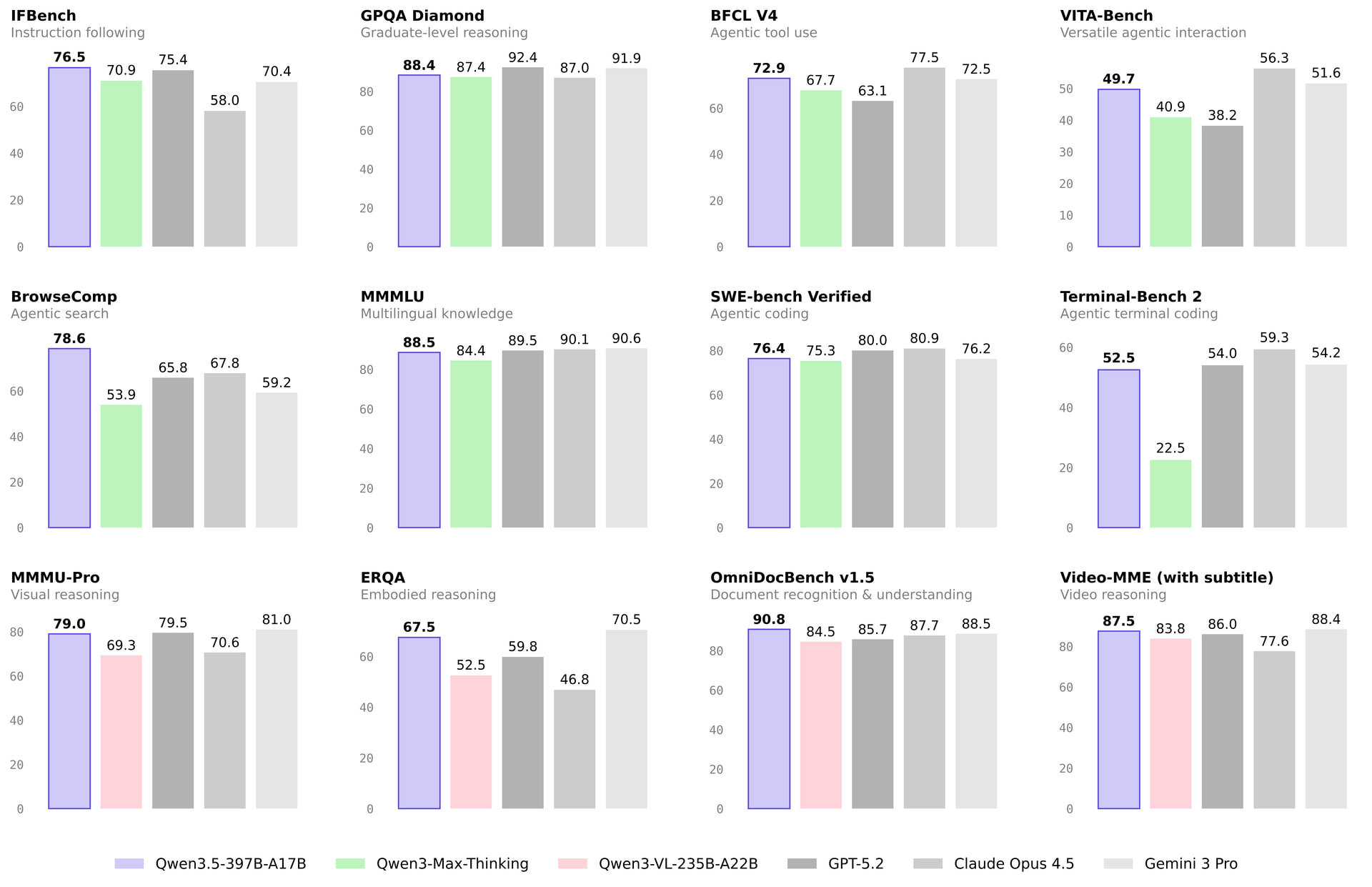
- 跑分霸榜:
- MMLU-Pro: 87.8 (超越 Kimi K2.5)
- MMLU-Redux: 94.9
- SuperGPQA: 70.4
深度观点
Qwen3.5 的发布标志着大模型竞争进入了“效能阶段”。不再盲目堆砌参数,而是通过架构创新让模型更轻、更准。对于开发者来说,更低的推理成本和原生的 Agent 能力将极大地拓宽应用边界。
了解更多详情: Qwen 官方博客 - Qwen3.5 发布