我昨天在z.ai chat上面测试了一下,感觉略显失望,因为有些单页网页任务感觉不太好。和4.7相比提升有限。
但是现在真正用它写代码,发现它逻辑真的很强,修复起来主打一个快准狠。而且一改之前的面貌,glm5没有给我过度自信的感觉,性格和k2.5有点类似。
看来这代是往软件工程发展了,挺好的。比那种号称 “一句话生成应用” 要务实很多!
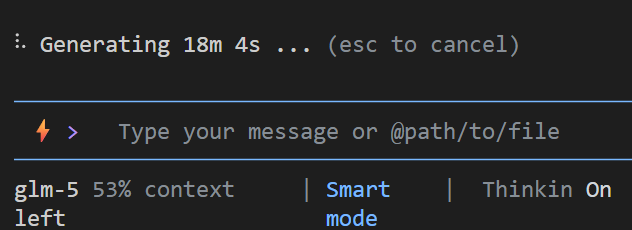
(图片):不是卡了,是它跑了18分钟,一次性完成了一个很长的任务。这种能力只有在k2.5上我才看到过(甚至比k2.5还要强)。
我昨天在z.ai chat上面测试了一下,感觉略显失望,因为有些单页网页任务感觉不太好。和4.7相比提升有限。
但是现在真正用它写代码,发现它逻辑真的很强,修复起来主打一个快准狠。而且一改之前的面貌,glm5没有给我过度自信的感觉,性格和k2.5有点类似。
看来这代是往软件工程发展了,挺好的。比那种号称 “一句话生成应用” 要务实很多!
(图片):不是卡了,是它跑了18分钟,一次性完成了一个很长的任务。这种能力只有在k2.5上我才看到过(甚至比k2.5还要强)。
但是200k还是略短一点。
不多奢求,我真的很希望下一代能给256。
现在用就提示超限了,只能等稳定后再用 ![]()
个人感觉glm5幻觉率低很多,做代码审查,k2.5能指出很多无中生有的问题,4.7时灵时不灵,容易找不到关键问题,修复问题的体验,k2.5和4.7半斤八两,真没感觉2.5比4.7好多少。glm5现在还没法细测,高并发卡也容易超限,目前用了大约600wtoken,幻觉率低很多,但是感觉上下文好短,运行一个任务就只剩40%上下文了
我基本和你一致,但我感觉k2.5比4.7厉害一点点,可能是我个人喜欢kimi。
现在是 glm5 > k2.5 > glm4.7 ≈ m2.1 大概这样
我觉得glm5稳定很多。其实k2.5也有改进。最差的就是4.7(其实更差的是4.6,这几个模型一个比一个进步)
我让kimi找性能问题,然后发给glm5让它检查,要不是glm5多个心眼,kimi早就瞎改一通了
我也超限
k2.5主要是幻觉率太高了,虽然是后出的模型,性能比4.7强,但是他的幻觉率让我头疼的很,所以我把他和4.7排一档,至于m2.1,上下文长度太抽象了,和ds坐一桌吧
晚点试一下
glm5是模型本身速度慢,还是iflow官方限制了呢,我总感觉很慢
估计都有。
我现在是k2.5和glm5来回用,衬托之下k2.5都变快了。