国产大模型再次刷新认知!权威评测机构 Artificial Analysis 刚发布了 GLM-5 的深度评测报告,数据非常震撼:GLM-5 不仅登顶开源榜首,更是历史上首个在智力指数上突破 50 分大关的开源模型!
==========================================
![]() 核心战绩:开源新王登基
核心战绩:开源新王登基
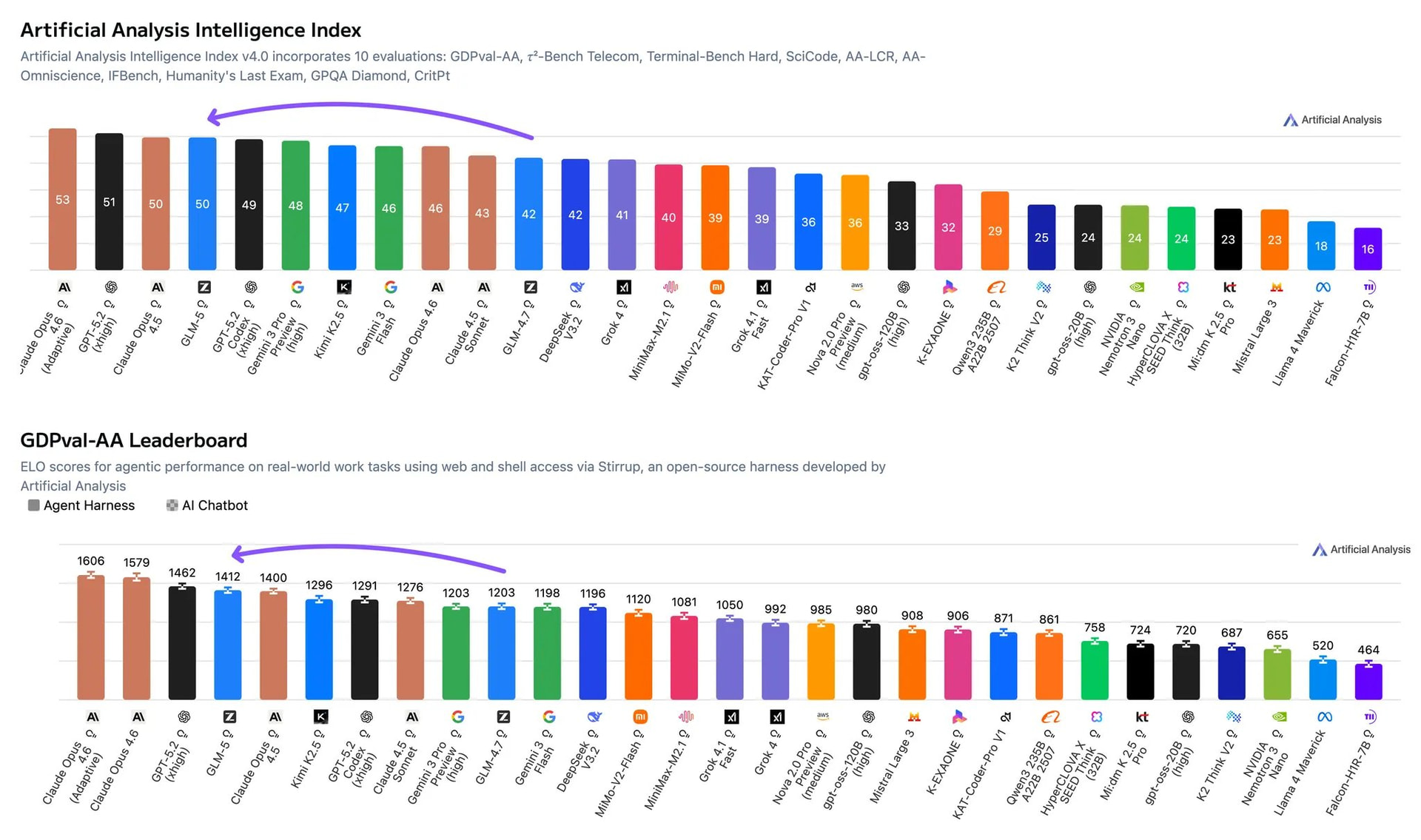
● 智力指数突破:GLM-5 得分 50 分(上一代 4.7 为 42 分),不仅是开源界第一,更首次缩小了开源与顶级闭源(如 Claude/GPT 系列)之间的鸿沟。
● 横向吊打:得分超过了此前表现强劲的 Kimi K2.5、MiniMax 2.1 以及 DeepSeek V3.2。
==========================================
![]() 智能体 (Agentic) 能力:只做有价值的事
智能体 (Agentic) 能力:只做有价值的事
● 全球第三:智能体指数得分 63 分,在开源模型中高居第一,全球总榜第三!
● 经济价值任务:在 GDPval-AA 评测(模拟演示文稿、数据分析、视频编辑等真实工作任务)中,Elo 分数达 1412,仅次于 Claude Opus 4.6 和 GPT-5.2 (xhigh)。
==========================================
![]() 幻觉控制:最“老实”的模型
幻觉控制:最“老实”的模型
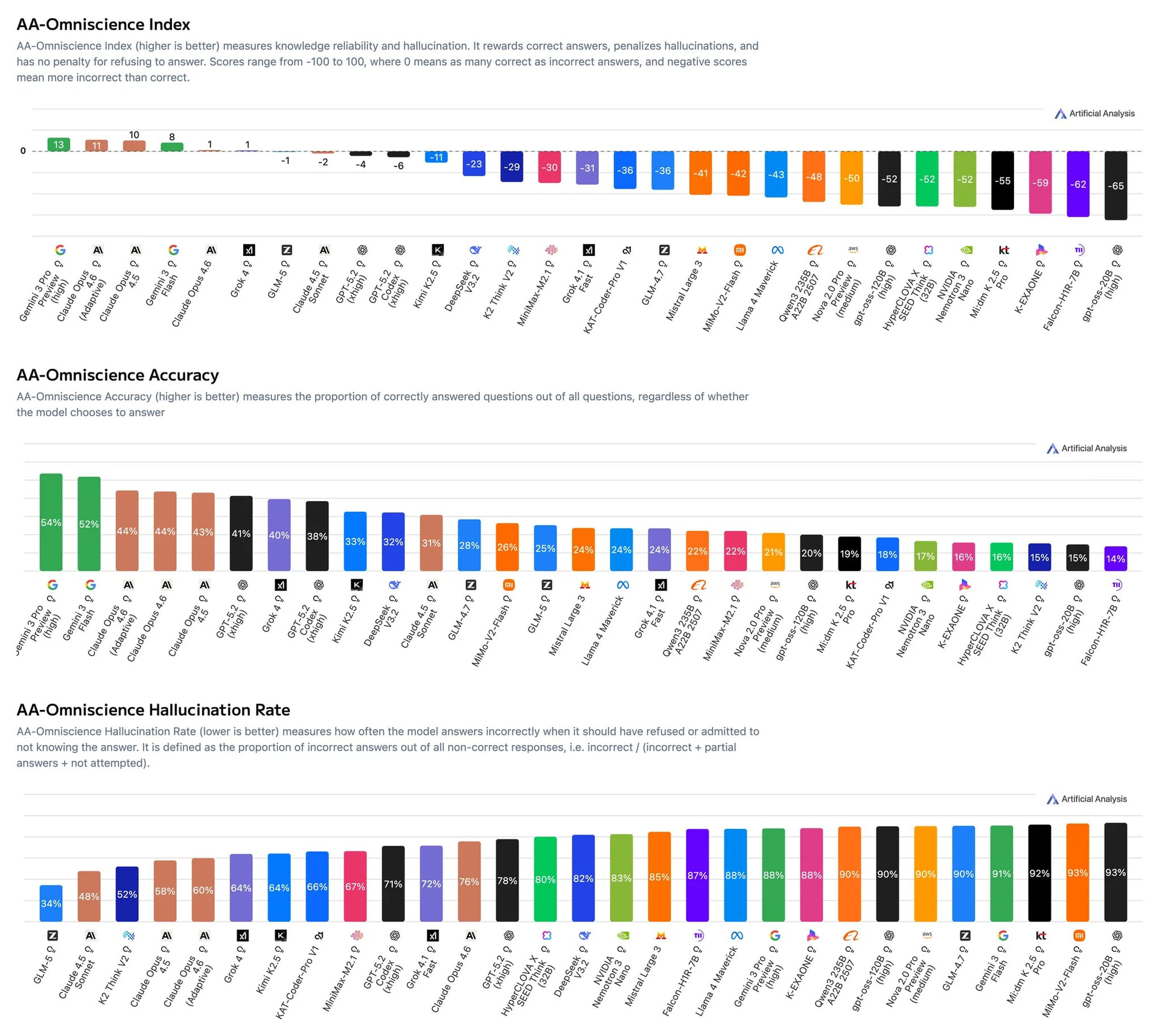
● 告别一本正经胡说八道:相比上一代,幻觉率大幅降低,AA-Omniscience 指数提升了 35 分。
● 机制优化:GLM-5 在不确定的情况下更倾向于拒绝回答,是目前所有测试模型中幻觉水平最低的。
==========================================
![]() 模型规格与技术细节
模型规格与技术细节
● 参数翻倍:从之前的 355B 规模提升至 744B (激活 40B),引入了 DeepSeek Sparse Attention 技术。
● 部署规格:原生 BF16 精度规模约 1.5TB。
● 协议利好:采用 MIT 开源协议!
● 训练量:预训练数据量从 23T 增加到了 28.5T tokens。
==========================================
![]() 总结
总结
GLM-5 的出现标志着开源模型正式进入了“50分智力俱乐部”。它在长任务逻辑、防幻觉以及真实经济价值任务(数据分析、复杂规划)上的表现,足以让它成为目前最适合构建 Agent 的基座。
数据来源:Artificial Analysis (@ArtificialAnlys)