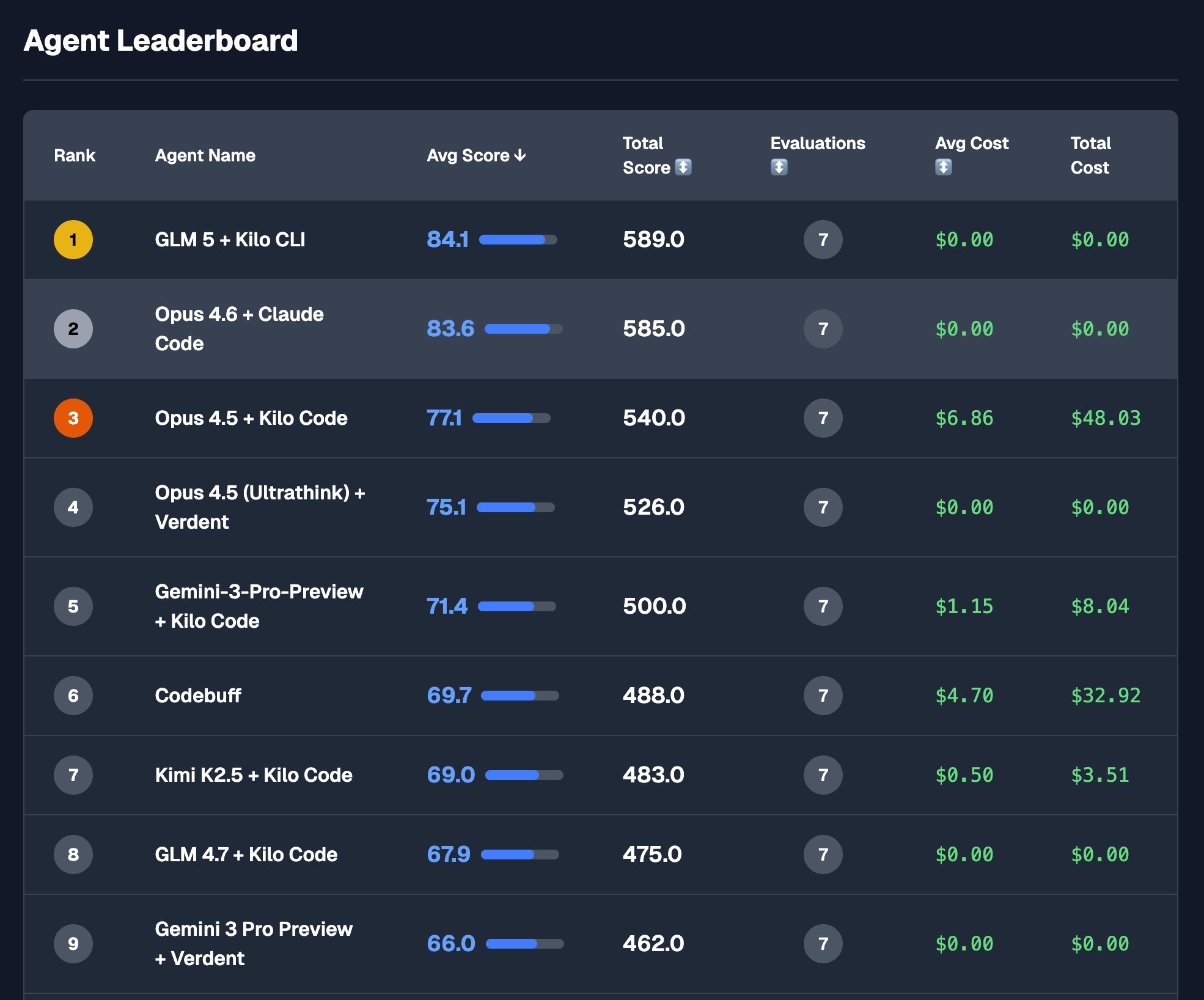
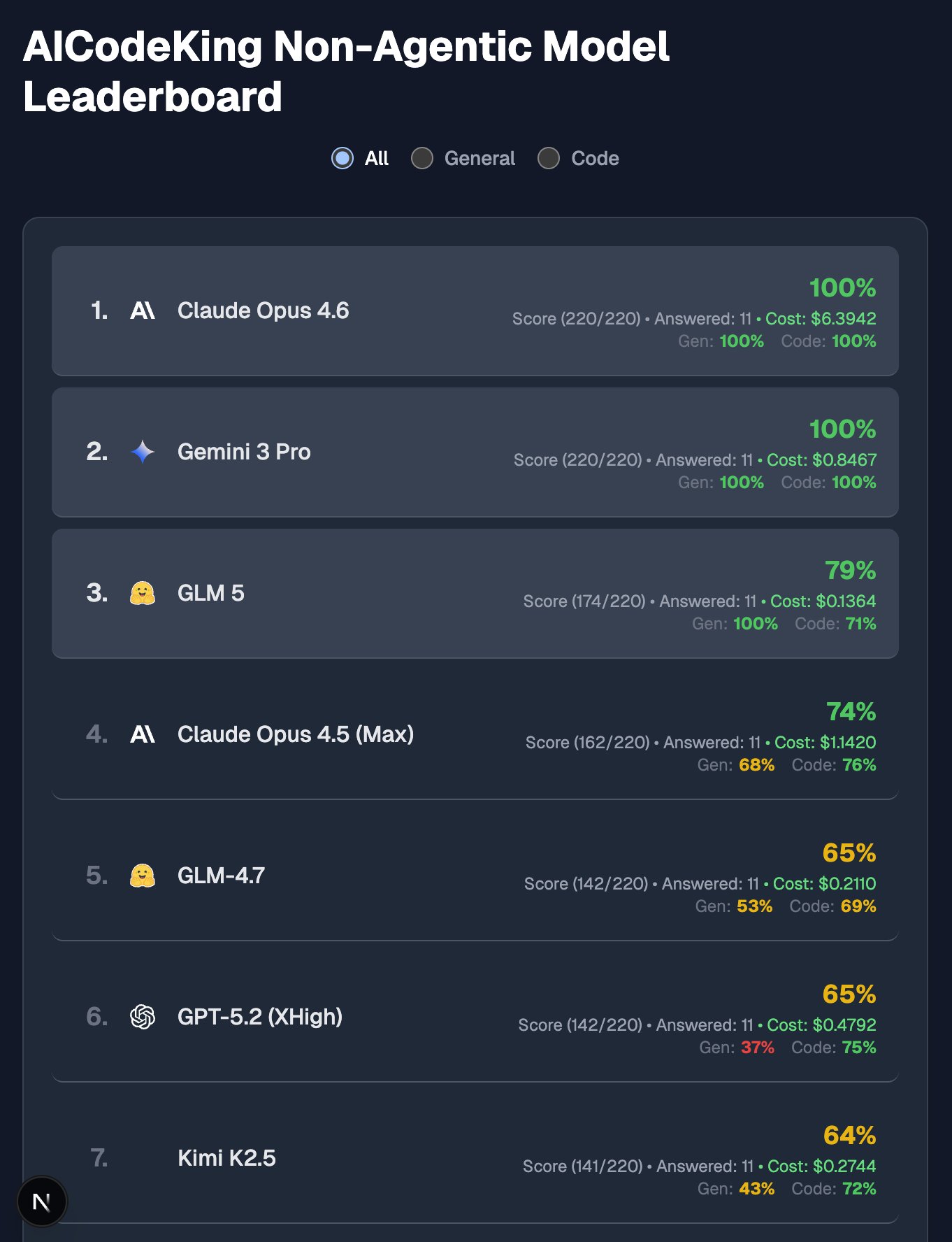
近期 GLM-5 的表现引爆了社区,基于早期测试者 @AICodeKingAICodeKingAICodeKingAICodeKing 的实测反馈,我们整理了这份深度分析,看看这款 744B 参数的大杀器究竟强在哪里:
==========================================
![]() 核心规格 (Specs)
核心规格 (Specs)
● 恐怖规模:7440亿 (744B) 参数,MoE 架构(每次推理激活约 40B),规模接近万亿级。
● 发布形式:将提供 Open Weights (开放权重)。
● 定位:推理模型 (Reasoning Model),API 极具性价比。
==========================================
![]() 为什么它是智能体 (Agentic) 之王?
为什么它是智能体 (Agentic) 之王?
博主称其为 “系统架构师” (System Architect),而不仅仅是写代码的:
- 顶级的规划能力 (Planning):这曾是 GLM 的短板,但在 GLM-5 上已进化到极致,能理解复杂产品架构,进行系统级自检。
- 真正的“爆肝”战士:擅长处理耗时多小时的长流程任务(实测连续工作 3 小时构建复杂应用而不中断)。
- 恐怖的自我修正:会主动运行 Lint 检查,甚至会主动调用 curl 测试前端错误(这是其他模型极少见的自主行为)。
- Agentic Leaderboard No.1:在构建复杂应用(Expo/Go/Nuxt)的实测中,生成的代码质量和功能完整性优于 Claude 4.6 Opus。
==========================================
![]() 它也有“硬汉”脾气
它也有“硬汉”脾气
● 不擅长闲聊:实干派模型,纯文本聊天和情感理解较弱。
● “想太多” (Overthinking):因为它满脑子都是架构和逻辑,在处理简单的 HTML/SVG(画个熊猫、写个布局)时反而容易把问题复杂化,这与 OpenAI Codex 的某些特质很像。
==========================================
![]() 总结
总结
GLM-5 牺牲了闲聊和简单视觉生成,换取了在架构设计、长期规划、自我纠错上的统治力。如果您需要构建复杂系统,它是比 Claude Opus 更好、更便宜的选择。
内容来源参考:AICodeKing (@AICodeKing) - https://www.youtube.com/watch?v=63Ail-fOrkM