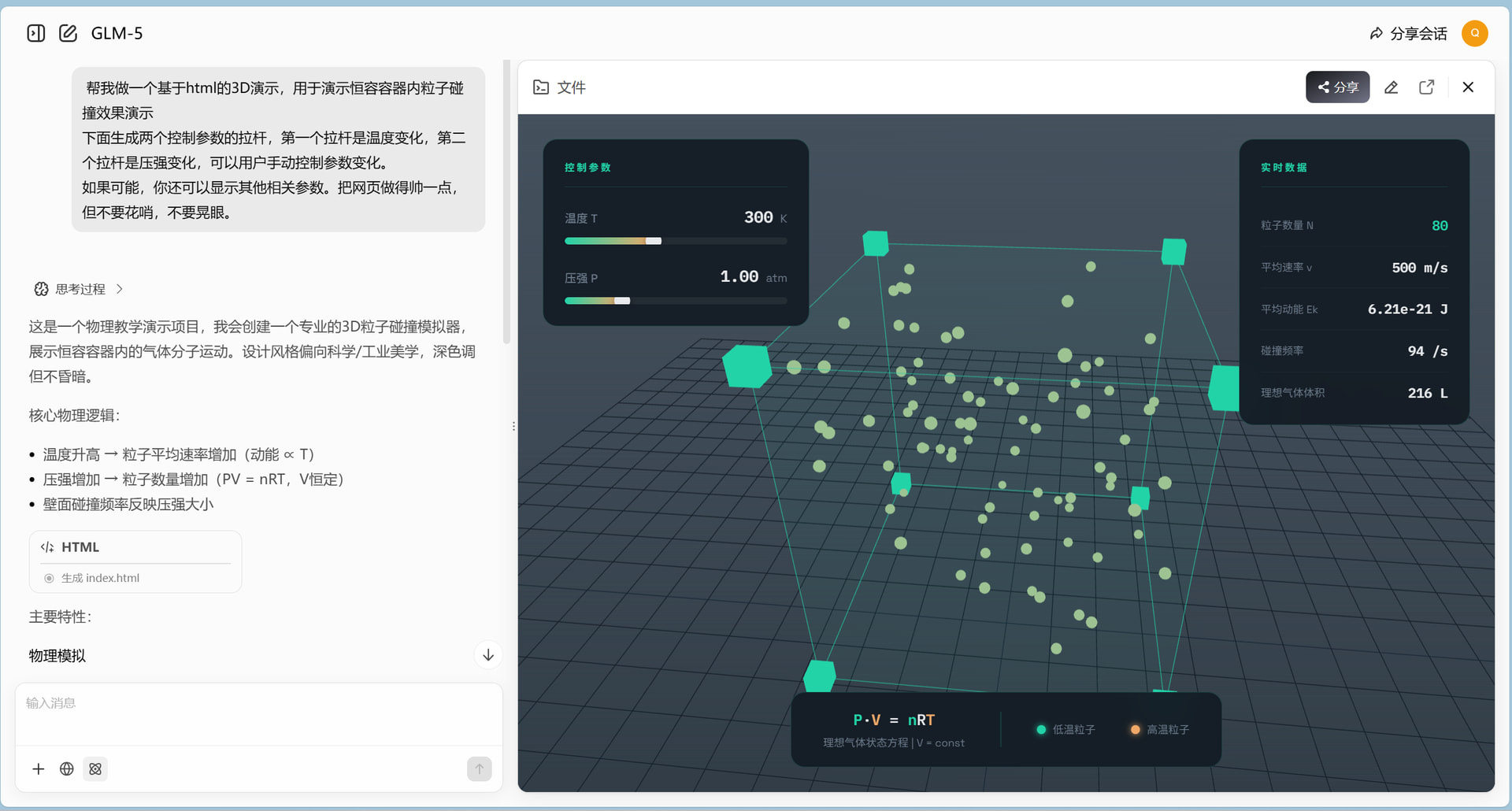
GLM-5 大模型终于发布了!看介绍感觉非常强劲。社区里的各位技术大佬们快快测起来啊!
在此抛砖引玉:
1. 大家觉得 GLM-5 的逻辑能力和生成速度如何?
2. 实际开发任务场景中,GLM-5 是否比 Kimi 2.5 更稳、更聪明?
3. 相比 Kimi 2.5 之前那个著名的“长思考”问题,GLM-5 的表现怎么样?
欢迎大家在评论区分享测试体感和对比案例!
哎嘿 ,晚上测一下
我觉得和4.7比是:大部分提升,部分超强,个别几个sota,小部分不如4.7。 只测了一点点,结论可能不完整。