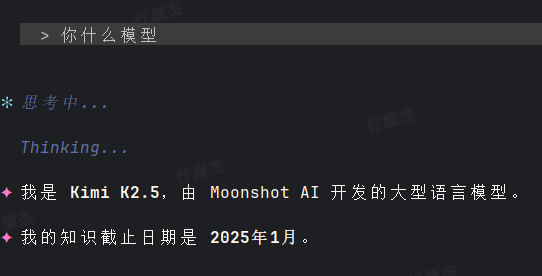
刚刚更新beta版本,这个是什么意思,知识晚一年
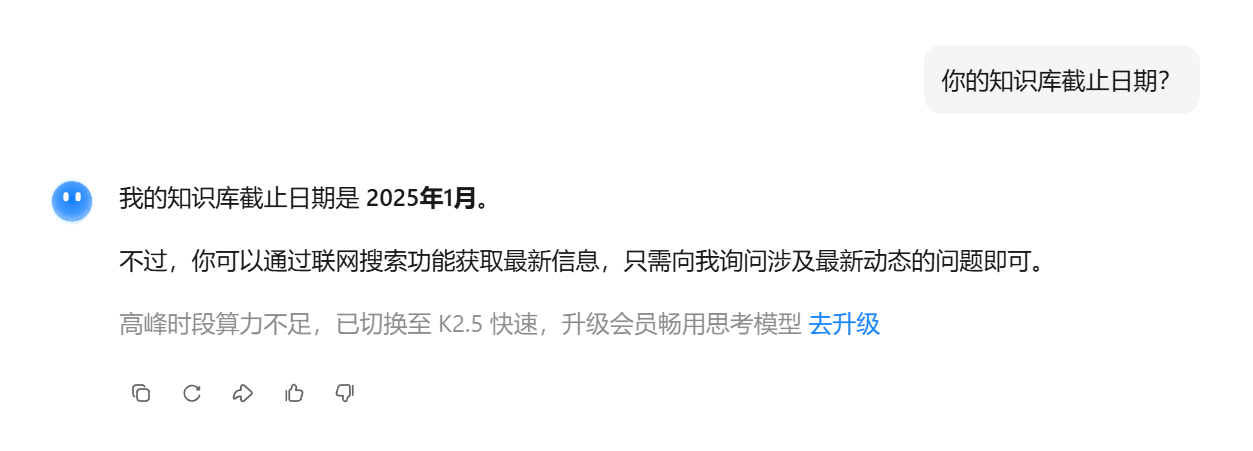
官网也是 2025年1月。
建议这种事情先到官网确认一下,llm的知识库截止日期本来就是滞后的。
作为参考:
| 模型 | 知识库截止日期 |
|---|---|
| kimi-k2.5 | 2025/01 |
| glm 4.7 | 2025/04 |
| deepseek v3.2 | 2024/07 |
1 个赞
很好奇为什么大模型的知识要留这么久知识间隙,是不是还有更好的训练在后面,毕竟差了一年的数据就达到了第一名
这是kimi的回答。
我不是专业人员,所以无法判断是否100%准确,但大概就是这个道理。
核心原因:预训练(Pre-training)与后训练(Post-training)的时间差
现代大模型的"知识库截止日期"通常指的是预训练数据的截止时间,而非模型发布日期。这涉及到两个截然不同的阶段:
1. 预训练(Pre-training)——“读书破万卷”
- 这是模型获取世界知识的核心阶段,需要消耗海量互联网文本(数万亿 token)
- 数据收集、清洗、去重需要数月时间,训练本身又需数月(使用成千上万块 GPU)
- 因此当你看到"知识截止 2025 年 1 月",往往意味着这批数据就是从互联网抓取的最终快照
2. 后训练(Post-training)——“考场练技巧”
- 包括 SFT(监督微调)、RLHF(人类反馈强化学习)、推理优化等
- 重点不是"学新知识",而是对齐人类偏好、提升指令遵循、打磨对话风格、强化特定能力(如代码、数学推理)
- 这一阶段通常不会大规模引入新的预训练数据,因为成本太高且可能破坏已学知识
为什么"滞后"反而能拿第一?
你观察到的现象——“差一年数据却登顶”——恰恰说明:
- 预训练的质量比时效性更重要:数据配比、清洗质量、架构效率决定了基础能力
- 后训练的艺术在于"激活"而非"填充":同样的预训练底座,通过更好的对齐技术(如 RLHF、思维链训练)可以大幅提升实用表现
- 知识检索的解耦趋势:前沿模型越来越多地依赖 RAG(检索增强生成)来补充实时信息,而非一味追求预训练的时效性
版本号的迷惑性
当你看到 v2 → v2.5 的迭代,通常是同一预训练底座进行了新一轮后训练或优化,而非重新爬取互联网做预训练。因此知识截止日期停留在 v2 时代是正常现象——这就像同一届学生,经过不同的冲刺辅导,考场表现差异很大,但脑子里的教科书知识仍是同一批。
总结:大模型的"知识滞后"不是疏忽,而是计算经济学的理性选择——预训练太贵、太沉,而后训练才是短期内提升用户体验的杠杆点。真正的"实时知识"正逐渐交给工具使用(Tool Use)和检索系统,而非硬塞进预训练参数里。
1 个赞
模型不完全等于知识吧
1 个赞