Hi,本周有奖互动话题为「iFlow CLI众多内置功能中,你最常用的是哪个?」
为了更好地帮助小白用户快速上手,我们想了解大家的使用习惯~ 
是 Workflow、Skills?还是 SubAgent、SubCommand?亦或是 MCP、Hooks?
 如果对这些功能感到上手困难,也欢迎提出你的疑问,我们将针对性地提供一些教程案例指导
如果对这些功能感到上手困难,也欢迎提出你的疑问,我们将针对性地提供一些教程案例指导 ~
~
欢迎在评论区分享你的使用体验和最爱功能!照例请 5 位云股东喝星爸爸 哦
哦
感谢大家的积极参与!
本期话题互动获奖的云股东有:
138****9546 10011955190
冷酷绝情反派 10004020184
ENFJ小太阳 10006361091
YK0524 10010408779
bingo906 10009891043
记得私聊 @菠菜水手边边 领取咖啡券哦~
1 个赞
用的最多的是/r功能拉回之前的聊天记录,感觉后面可以将这个放到主页面内,这样找回上次工作内容也方便,还有如果iflow有些时候需要使用某些功能或软件的时候发现没安装的话最好询问一下客户是否需要安装,若是10秒不做出选择则默认不安装
1 个赞
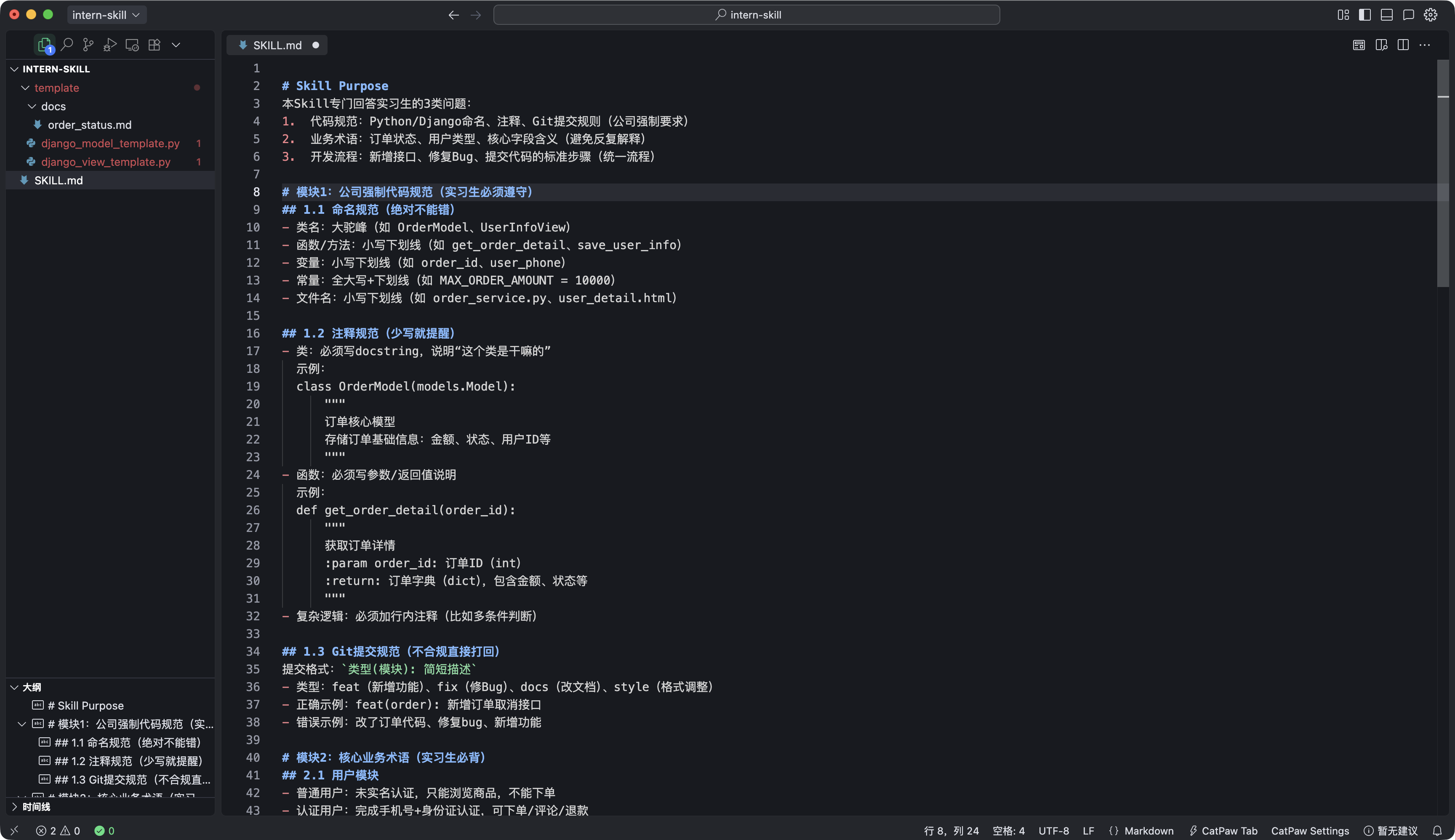
我来了,那必须是最近热门的skills,看到标题有小白,我就想做一个科普分享:
1.skills本质上就是一个说明书/成熟的体系,举例:我们最近招了一个实习生,对公司业务不熟悉,对代码规范不熟悉,每次让他写一个用户查询接口,你都要从头念叨一遍:
“先做参数校验,user_id 不能为空;返回格式必须是 {"code":0,"msg":"成功","data":{}};记得加异常捕获,别直接抛错;函数名要小写下划线,比如 get_user_detail;类视图要写 docstring 说明用途;还有别忘了在 urls.py 里配路由”
但是如果有了skills,你直接把这些接口开发规则,做成 「Django 接口开发规范 Skill」类似一本,说明书
以后不管实习生要写用户接口、订单接口还是商品接口,他只要打开iflow,安装这个 Skills,输入安装的名称(我的叫intern-skill),AI 就会直接给他:
-
接口开发的标准步骤(参数校验→业务逻辑→返回格式→路由配置)
-
可以直接复制的代码模板(带参数校验、异常捕获、规范注释)
-
禁止踩坑的注意事项(比如不能省略异常处理、返回格式不能乱改)
–——————————这个是吐槽线——————————-
第一次安装这个skills之后,我不知道是不是没有发布的原因,进入iflow后输入/名字,其实不会马上加载不出来,建议重启两次之后再试,官方快优化!!!!
2 个赞
以我们公司的具体案例来说:
场景 1:实习生的原始提问
实习生提问:
老师,我要在订单模块加一个 “根据订单 ID 查询订单详情” 的接口,该怎么写啊?要注意什么?还有写完怎么提交代码?
AI 基于 skill 的标准化回答
基于 XX 公司实习生指导规范,新增订单查询接口的完整步骤和要求如下:
第一步:接口开发规范(必须遵守)
-
函数名:小写下划线(如 get_order_detail);
-
返回格式:固定 {"code": 0, "msg": "成功", "data": {...}};
-
必须加参数校验、异常捕获、docstring 注释;
-
代码文件路径:apps/order/views.py(视图)、apps/order/urls.py(路由)。
第二步:开发步骤
-
编写视图函数(参考公司 Django 视图模板);
-
配置路由;
-
写单元测试(覆盖率≥80%);
-
Git 提交(格式:feat(order): 新增订单ID查询详情接口);
-
提 Merge Request,抄送你的导师审核。
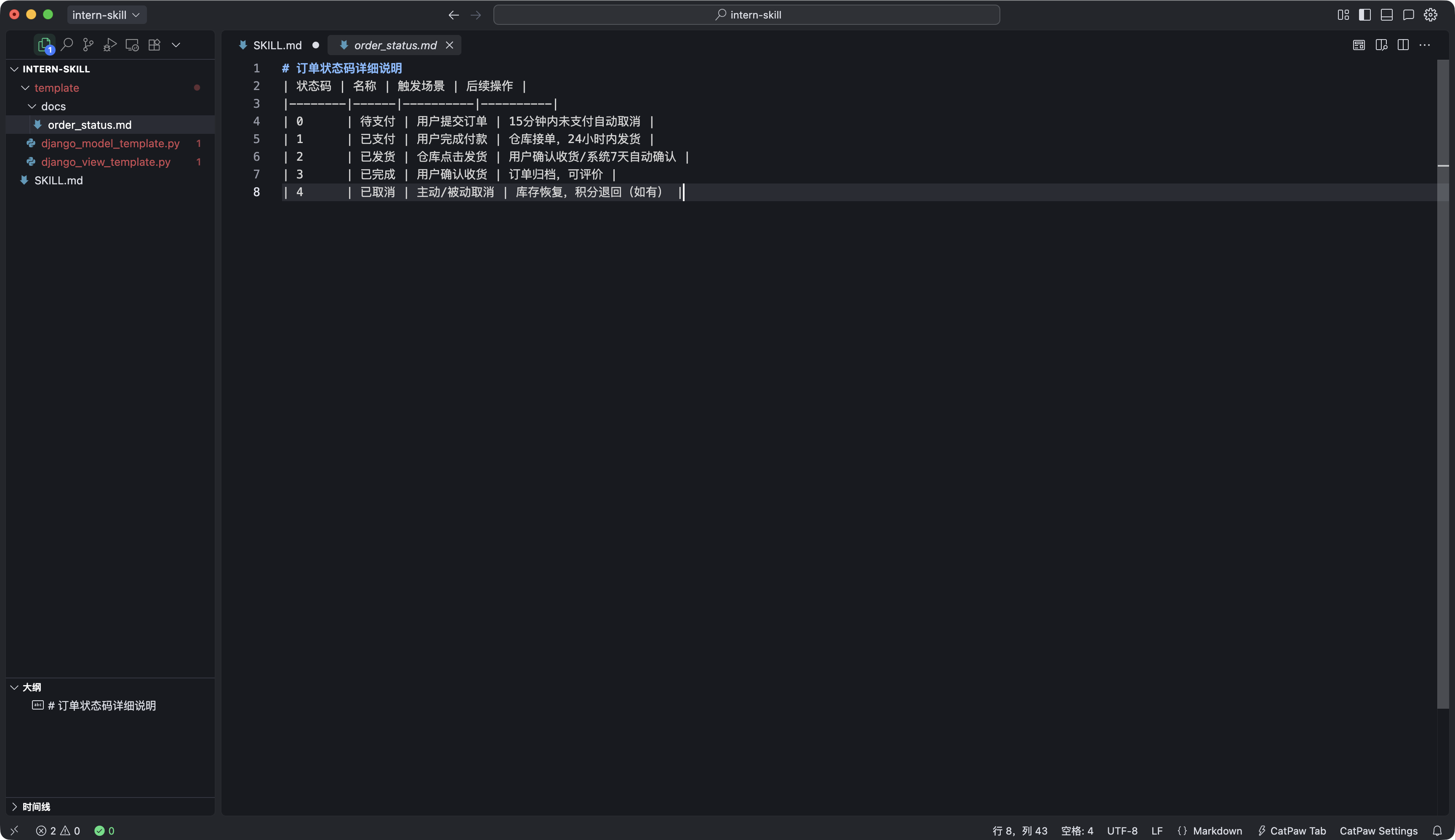
第三步:核心业务规则(订单状态码参考)
查询接口需返回完整订单状态:
参考代码模板
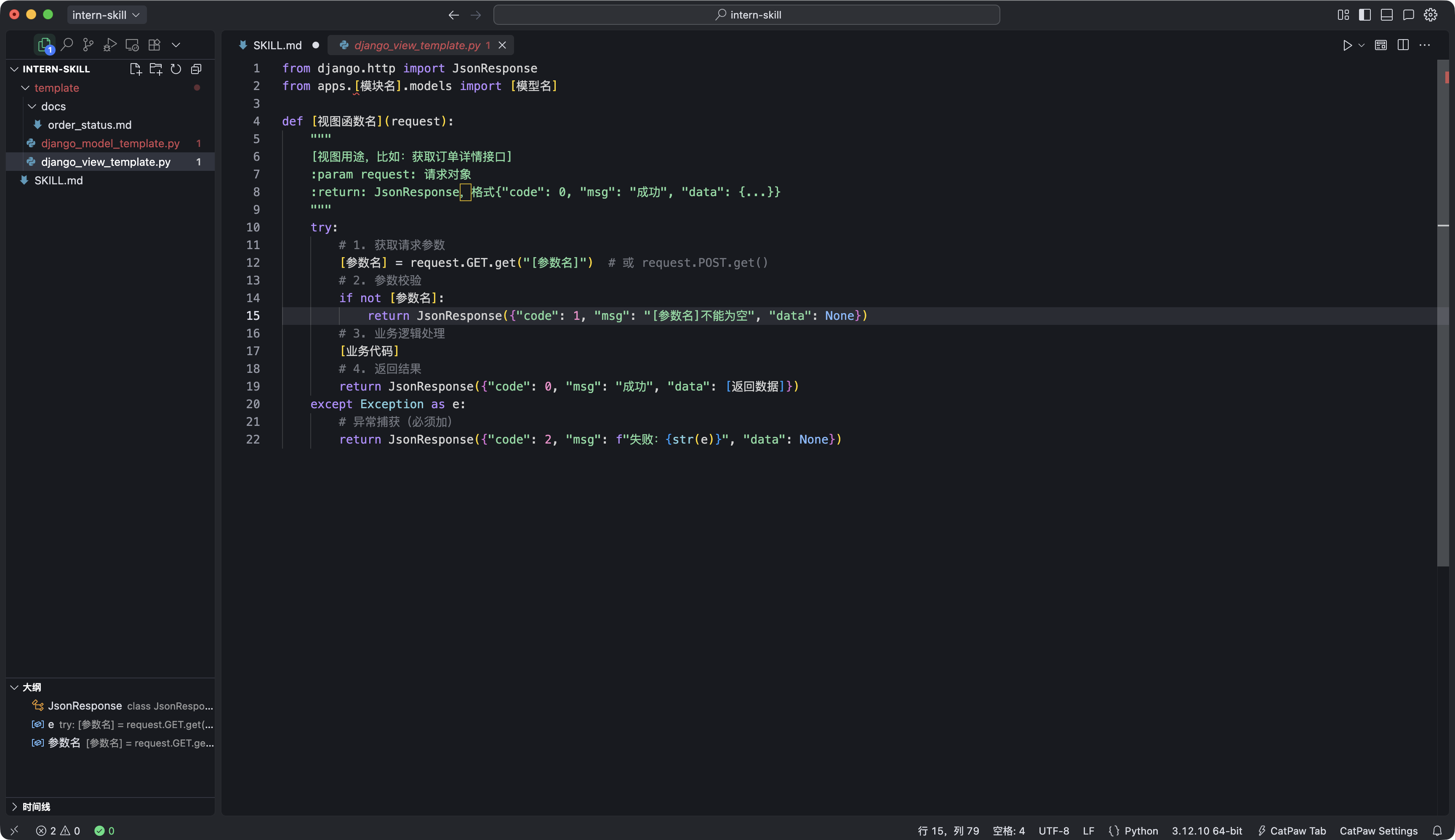
# 视图函数示例(apps/order/views.py)
from django.http import JsonResponse
from apps.order.models import OrderModel
def get_order_detail(request):
"""
根据订单ID查询订单详情接口
:param request: 请求对象,需传order_id参数
:return: JsonResponse,格式{"code": 0, "msg": "成功", "data": {...}}
"""
try:
# 1. 获取并校验参数
order_id = request.GET.get("order_id")
if not order_id or not order_id.isdigit():
return JsonResponse({"code": 1, "msg": "订单ID不能为空且必须为数字", "data": None})
# 2. 业务逻辑:查询订单
order = OrderModel.objects.filter(id=order_id, is_delete=False).first()
if not order:
return JsonResponse({"code": 2, "msg": "订单不存在", "data": None})
# 3. 组装返回数据(含状态码业务逻辑)
order_data = {
"order_id": order.id,
"user_id": order.user_id,
"amount": float(order.amount),
"status": order.status,
"status_name": "",
"create_time": order.create_time.strftime("%Y-%m-%d %H:%M:%S")
}
# 状态码1(已支付)的额外业务逻辑
if order.status == 1:
order_data["status_name"] = "已支付"
order_data["expect_delivery_time"] = (order.create_time + timedelta(hours=24)).strftime("%Y-%m-%d %H:%M:%S")
elif order.status == 0:
order_data["status_name"] = "待支付"
elif order.status == 2:
order_data["status_name"] = "已发货"
elif order.status == 3:
order_data["status_name"] = "已完成"
elif order.status == 4:
order_data["status_name"] = "已取消"
# 4. 返回结果
return JsonResponse({"code": 0, "msg": "成功", "data": order_data})
except Exception as e:
return JsonResponse({"code": 999, "msg": f"查询失败:{str(e)}", "data": None})
第二个真实场景:
实习生提问:
老师,订单状态码 1(已支付)除了要返回预计发货时间,还有什么业务限制吗?比如能不能取消?
AI 基于 Skill 的回答:
结合 XX 公司订单业务规则,状态码 1(已支付)的核心业务限制如下:
-
取消规则:已支付订单用户可在支付后 2 小时内取消,超过 2 小时需联系客服(系统不允许自主取消);
-
库存规则:订单支付后,对应商品库存会锁定,24 小时内未发货自动解锁(避免库存长期占用);
-
退款规则:取消后退款会在 1-3 个工作日原路返回,VIP 用户优先到账(1 小时内);
-
接口返回要求:必须包含expect_delivery_time字段(支付时间 + 24 小时),否则前端会报错。
2 个赞
文件结构:
核心文档:skill.md 规范+业务+流程
辅助模板:代码实例,视图开发模板,模型开发模板
业务状态码补充:业务资料(订单状态码说明,用户类型说明)
1 个赞
哈哈哈,自从更新之后我的Hooks的结束通知就成为了一个多余的内容一样,不过真的很喜欢当前的SnoreToast  ;因为也是设置了一个弹窗:
;因为也是设置了一个弹窗:
;哦豁好像又有一点不一样,一个是对话完成,一个会话结束;好吧看来Hooks还可以保留。

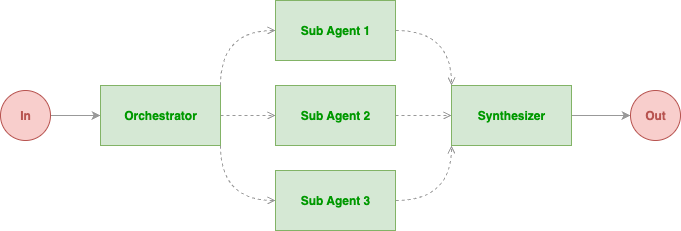
第二个喜欢的就是subagent;因为这个自定义创建给了很多种可能,对于一般的内容,可以直接通过两个或者一个subagent就可以配合主Agent形成一个合作式生成的过程,比如说:
官方的商店里面有一个search-specialist的subagent就可以用来
$search-specialist 某个你想到的主题,然后生成这个主题所需要的关键内容和你想要调研的内容;或者是完成了你想要完成的代码,但是可以先用Agent进行一次代码审查 $coder-reviwer;$错误侦探 correr -detecter;哈哈哈,这样可以实现一次简单的衔接模式;利用subagent的信息进行整合;
注意还可以进行自行调节是否需要集成主Agent的能力或者工具,MCP等,这可以进行约束其工作范围。
第三个就是工作流
事实上想要组成一个deep reasearch也可以通过加入其余的subagent进行架构设计比如说:
当前查询的关于一个deep research的调研工作流同样的就可以设置多个subagent工作流程
哈哈哈,下面是用千问进行生成的一个基本流程;但是可以通过如下方式
/qa 根据以下的八个模块分别生成八个subagent;将8个subagent最终按照如下过程集成为一个工作流,并进行运行测试。
该工作流的目标是构建一个deep reasearch;根据各个模块的内容配置相应的model,因此需要对model进行分析各自的优势,model:【此处最好限定在iflow 自定义的这几款模型】;
注意subagent 的格式 以及工作流的格式需要符合官方定义流程。
1. 查询分解与意图分析
- 系统首先解析用户的高层次、复杂且模糊的查询(如"帮我生成一份关于Deep Research的技术报告")
- 识别用户潜在意图,并将大问题分解为一系列更小、离散且可独立研究的子问题
- 例如:Perplexity的"Pro Search"功能会将复杂提示分解为多个子查询
2. 动态任务规划
- 制定多步骤的执行计划,而非静态脚本
- 识别任务间的依赖关系,确定哪些可以并行执行,哪些必须按顺序执行
- 例如:OpenAI Deep Research在执行前会将"多点研究计划"呈现给用户进行审查
3. 信息检索
- 查询扩展 :生成同义词、相关概念,扩大搜索范围
- 查询分发 :针对多样化的数据源执行多个并行查询
- 重排序与过滤 :对检索结果进行处理,去重、过滤低质量来源,根据语义相关性重排序
4. 执行引擎(ReAct框架)
Deep Research系统通常采用ReAct框架进行执行:
- 思考(Thought) :Agent内部推理,思考当前状态、已收集信息及下一步行动
- 行动(Action) :执行具体工具调用(如调用搜索引擎API、代码解释器)
- 观察(Observation) :获取行动结果,用于下一步推理
5. 动态验证机制
- 采用三重交叉验证系统(Triple-Check Verification)比对不同来源信息
- 对检索到的数据的质量、相关性和潜在偏见进行推理
6. 深度分析引擎
- 应用高级推理模型(如OpenAI的o3框架)进行数据关联分析
- 识别潜在模式和矛盾点
- 例如:OpenAI o3框架相比GPT-4在多步推理能力上提升133%
7. 自适应报告生成
- 根据用户需求动态调整报告结构
- 支持技术文档、商业简报、学术综述等多种格式
- 附带权威数据来源索引,确保答案可追溯
8. 闭环迭代
- 系统会根据已获取信息不断调整搜索策略
- 例如:dify模板中的工作流会根据depth参数进行多轮搜索
- 通过迭代过程逐步完善报告内容
;
哈哈哈,也可以进行拆解其他的流程,比如说想要将一个复杂的工作流;处理一段定义好的如何处理数据的流程也可以直接要求其按照特定的步骤进行处理;也是一个工作流;
嘿嘿 
Subcommand真的也很不错诶,比如说想要直接调用ollama;其余兼容的APi都可以集成为一个subcommand来进行调用其余API来回复问题,类比与subagent吧,不过需要你自定义的进行重构提示词模块 。
我去,好像又偏题了  ;哈哈哈
;哈哈哈
1 个赞
SubAgent功能绝对是各行业都能上手的,他可以把你的组织拆分成单独的具有特定功能的处理专门事物的智能体,比如一个医院可以分成(咨询护士:识别用户意图(问诊/诊断/闲聊)、分诊护士:当信息不足时(如只说“肚子痛”),会追问细节而不是直接给建议、资深医生:仅在信息充分时给出专业建议,且遵循“分析 → 建议 → 就医”的顺序)写公众号文章可以分成(创意官:专门负责想标题和选题、编辑:负责把我的草稿弄成通顺的文章、配图师:负责生成提示词去画图),这样当用户询问的时候每个智能体处理该处理的事情就像是一个团队一样,如果有小伙伴不知道具体怎么实现可私聊我会进行回复
3 个赞
说个最实用的-SKILLS,可以让iflow在组织维度形成规模化,降低边际成本。
- 理由 ,一个好的SKILLS就是一个SOP。一套好的代码可以在不同业务里,让AI模仿,重复利用。(SKILLS)
- 优势: 可复用、规范化, 实现质量不再由单一的工程师水平决定。
- 举例: 数据库建表规范、图片上传组件、文件上传组件。
- SKILLS实现了优秀方法论共享
原提示词:
帮我创建一个用户表 , 包含用户手机号姓名…
效果: 完成基础建表语句,但是索引、表名、系统字段不符合内部规范。
现提示词:
使用 db-design SKILLS 帮我创建一个用户表 , 包含用户手机号姓名…
效果:完美匹配
1 个赞