你用的是什么agent,什么模型?我iflow,glm-5.1几个问题就给我6000了
我用的jd的coding plan,不是某山的,某山的就是消耗快,你用啥它都快 ![]()
10点半一点,结果实名认证完回来又售罄了。
明天继续
首购优惠显示19.9,你咋搞到的9.9的,牛啊
最开始7.9,后来涨价了一次
但是好像限制QPS了,请求返回变慢了,之前用CoderChat一天轻松可以到700请求,现在多开窗口也只能到300多,不过总体还可以接受
从4月中开始就加了tps和qps的限制,不加的话以当时的资源根本扛不住,完全没法用,太慢,加完后速度快了很多,就是有时会触发limit,一开始遇到频率比较高,后来基本上不怎么遇到了,就是报错的频率上来了
不过有一说一,7.9那真是厂家纯赔,就是引流用的,19.9甚至40其实也赔,当然如果玩虾的没那么多,还稍微好一点点,还能拿到coding的数据训练用,但是京东又不推自己的大模型,所以也不知道它怎么打算的,还是就厂商也焦虑看别人家出自己也跟进出…
也是开始耍猴了
还是算力的原因吧,jd的卡应该不多,今天下午又开始各种报错了
不是吧,我还没抢到就没了么
中
中
中
中
中
俺不中咧
求求你,别中了 ![]()
![]()
![]()
刚刚突发奇想,在 opencode 里写代码时,切换不同供应商的模型,会不会导致成本上升
因为觉得上下文缓存不是共享的,切换供应商会硬吃一发超长的未命中缓存,但是 coding plan 是按次数算的,不知道有没有影响
于是去让 ai 帮忙查一下,结果火山被抓典型了 ![]()

公认的坑了
所以说,jd这种老老实实计次的,真是老实孩子了
1 个赞
大佬大佬,求助,讯飞的coding plan,opencode里如何配置开启思考
这个我不知道 ![]() 看看讯飞的文档里里有没有写
看看讯飞的文档里里有没有写 ![]()
火山里配置是这样的
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"volcengine-plan": {
"npm": "@ai-sdk/openai-compatible",
"name": "volcengine",
"options": {
"baseURL": "https://ark.cn-beijing.volces.com/api/coding/v3",
"apiKey": "<ARK_API_KEY>"
},
"models": {
"<Model_Name>": {
"name": "<Model_Name>",
"options": {
"thinking": {
"type": "enabled"
}
}
}
}
}
}
}
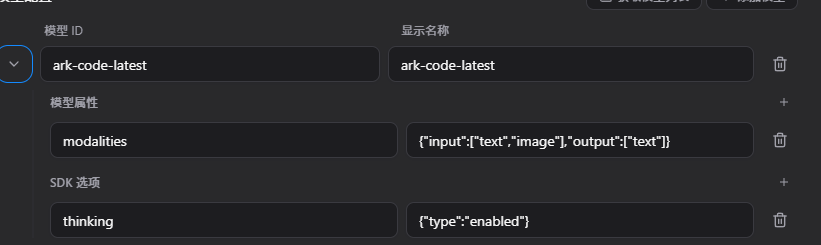
对应 cc switch 里面是这样的, sdk 选项 → key:thinking, value: {"type":"enabled"}
1 个赞