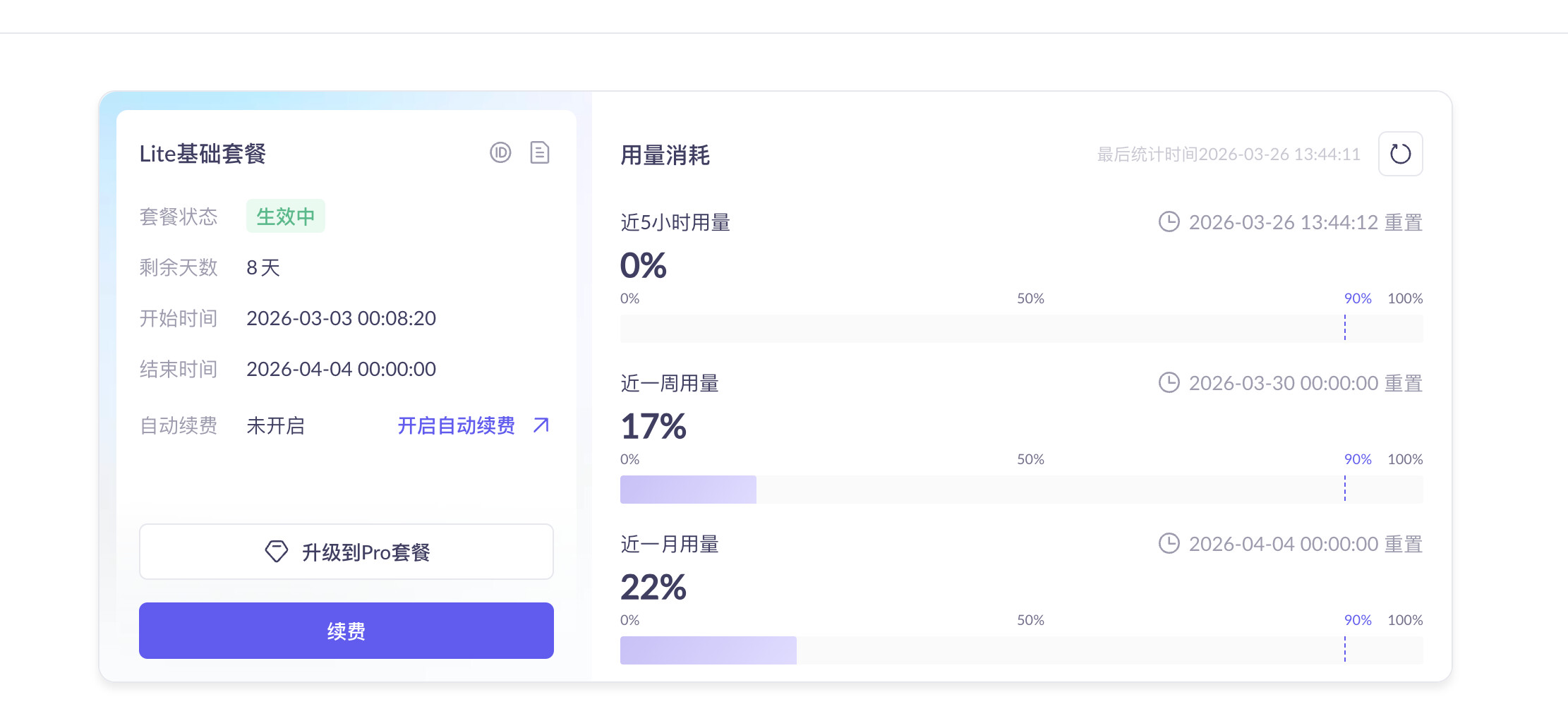
大致信息分享:
时间
- 每日上午 10:30 限量开放新用户首购特惠名额。记得参与前账号实名
套餐信息
买的7.9入门款,订阅如下:
- Coding Plan Lite套餐:订阅时长1个月,新用户首订特惠价7.9元;售完可购买原价套餐:40元/月
- Coding Plan Pro套餐:订阅时长1个月,新用户首订特惠价39.9元;售完可购买原价套餐,200元/月
用量限制
| 套餐 | 适用人群 | 用量限制 |
|---|---|---|
| Lite套餐 | 中等强度的开发者,适合大多数开发者。 | 1. 每5小时:最多约 1,200 次请求。 2. 每周:最多约 9,000 次请求。 3. 每订阅月:最多约 18,000 次请求。 |
| Pro套餐 | 复杂项目开发,适合高强度工作的开发者。 | Lite套餐的5倍用量。 1. 每5小时:最多约 6,000 次请求。 2. 每周:最多约 45,000 次请求。 3. 每订阅月:最多约 90,000 次请求。 |
支持 Claude Code、OpenCode、OpenClaw、Roo Code、Cursor等主流 AI 编码工具,多工具之间套餐额度共享。
API地址
![]() OpenAI 兼容协议 URL
OpenAI 兼容协议 URL
https://modelservice.jdcloud.com/coding/openai/v1
![]() Anthropic 兼容协议 URL
Anthropic 兼容协议 URL
https://modelservice.jdcloud.com/coding/anthropic
model
支持配置的 Model Name:
- DeepSeek-V3.2
- GLM-5
- GLM-4.7
- MiniMax-M2.5
- Kimi-K2.5
- Kimi-K2-Turbo
- Qwen3-Coder
模型详情
| 模型名称 | 模型介绍 | 说明 |
|---|---|---|
| DeepSeek-V3.2 | 平衡推理能力与输出长度,在通用问答、Agent 任务、轻量级代码开发中稳定高效。默认包含深度思考(支持关闭)。 | 长度限制如下: 1. 上下文窗口:128k 2. 最大输出长度(包含思维链):64k 3. 默认关闭思考,支持开启 |
| GLM-5 | 专注于复杂系统工程和长周期智能体(Agent)任务。 | 长度限制如下: 1. 上下文窗口:200k 2. 最大输出长度(包含思维链):32k 3. 默认开启思考,支持关闭 |
| GLM-4.7 | 智谱 AI 旗舰代码大模型,轻松解析超长代码库,在代码生成、调试、全链路理解场景表现优异。 | 长度限制如下: 1. 上下文窗口:200k 2. 最大输出长度(包含思维链):128K 3. 默认关闭思考,支持开启 |
| MiniMax-M2.5 | MiniMax 旗舰级开源大模型,在编程、工具调用、搜索等生产力场景达到行业领先水平。 | 长度限制如下: 1. 上下文窗口:200k 2. 最大输出长度(包含思维链):128k 3. 默认开启思考,支持关闭 |
| Kimi-K2.5 | Moonshot AI 最新编程模型,进一步强化了前端代码质量与设计表现力。 | 长度限制如下: 1. 上下文窗口:256K 2. 最大输出长度(包含思维链):32k 3. 默认开启思考,支持关闭 |
| Kimi-K2-Turbo | Kimi K2 的高速版本,参数一致但输出提速至 60-100 token/s。 | 长度限制如下: 1. 上下文窗口:256K 2. 最大输出长度(包含思维链):32k 3. 默认关闭思考,支持开启 |
| Qwen3-Coder | Qwen(通义千问)系列迄今为止最具 Agent 代理能力的代码模 | 长度限制如下: 1. 上下文窗口:64K 2. 最大输出长度(包含思维链):8K 3. 默认关闭思考,支持开启 |
根据模型详情可在claude code、openclaw中配置斟酌多个适配模型, 减少不必要的浪费.
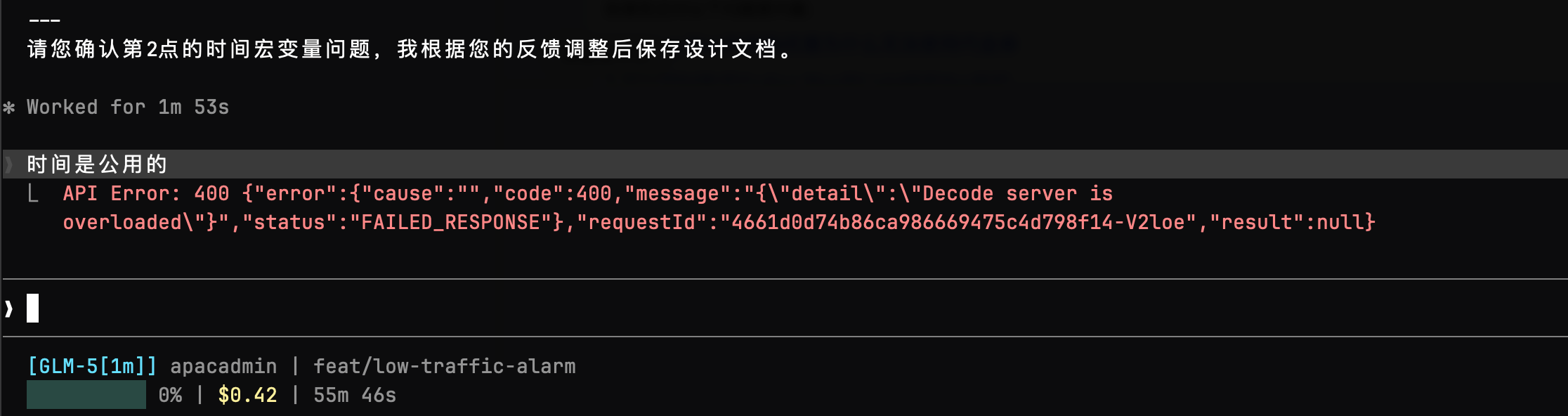
用了几天了,用量不算太多. 目前感受速度可以,但是glm5存在问题.
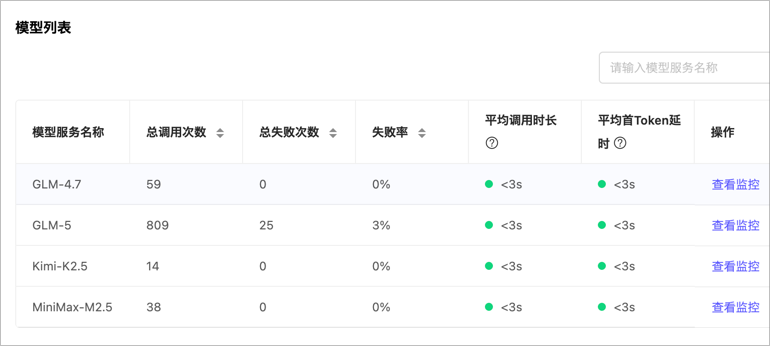
从统计上可以看出来, glm5 存在失败问题. 就是你跑着跑着就报错了.
报错但不止当前错误: