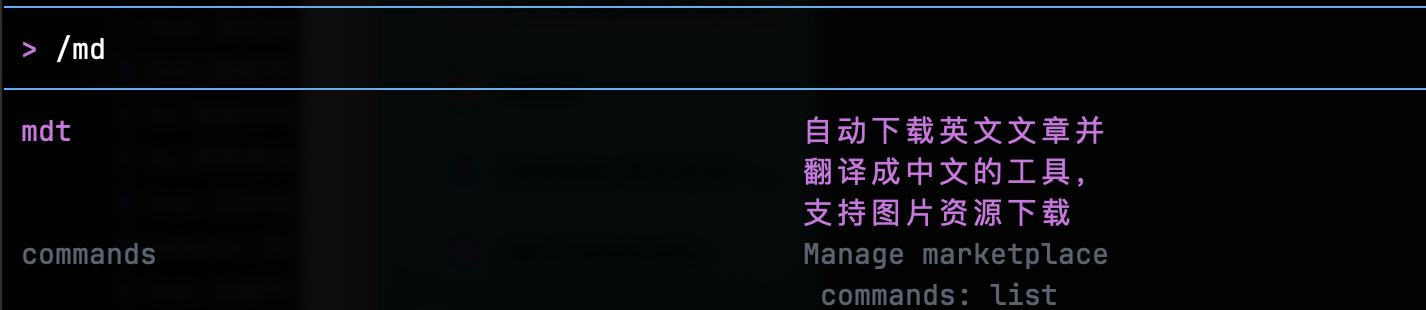
使用iFlow创建自定义Command:网页文章下载与翻译工具
环境信息
- iFlow版本:v0.3.28
- 使用模型:GLM-4.6
- 文档日期:2025年11月28日
背景和需求
作为技术人员,我经常需要阅读海外技术文章和文档。由于英文水平有限,通常需要通过浏览器插件进行翻译。同时,为了长期保存有价值的内容,需要将喜欢的文章收藏到本地。
面临的主要问题:
- 语言障碍:英文技术文档阅读效率低
- 链接失效风险:网页内容可能随时间消失
- 浏览器插件限制:功能单一,难以批量处理
- 资源分散:图片等资源容易丢失
基于这些痛点,我决定利用iFlow平台开发一个自动化工具,实现网页内容的下载、格式转换和翻译功能。
需求分析
在开始实现之前,我明确了以下核心需求:
功能需求
- 网页内容下载:获取指定URL的完整HTML内容
- 格式转换:将HTML转换为干净的Markdown格式
- 资源处理:下载并本地化所有图片资源
- 自动翻译:将英文内容翻译为中文
- 文件管理:规范的文件命名和目录结构
技术需求
- 无外部API依赖:利用iFlow内置AI能力
- 错误处理:网络异常、格式转换失败等场景
- 批量处理:支持多个URL处理
- 可配置性:支持不同参数组合
用户体验需求
- 简单易用:单一命令完成所有操作
- 进度反馈:实时显示处理进度
- 结果清晰:明确的输出文件位置
实现过程
我先通过自然语言告诉他这个任务:
帮我将网页内容下载到本地以markdown格式保存,存好后将文章翻译成中文。 地址是: xxx
结果:
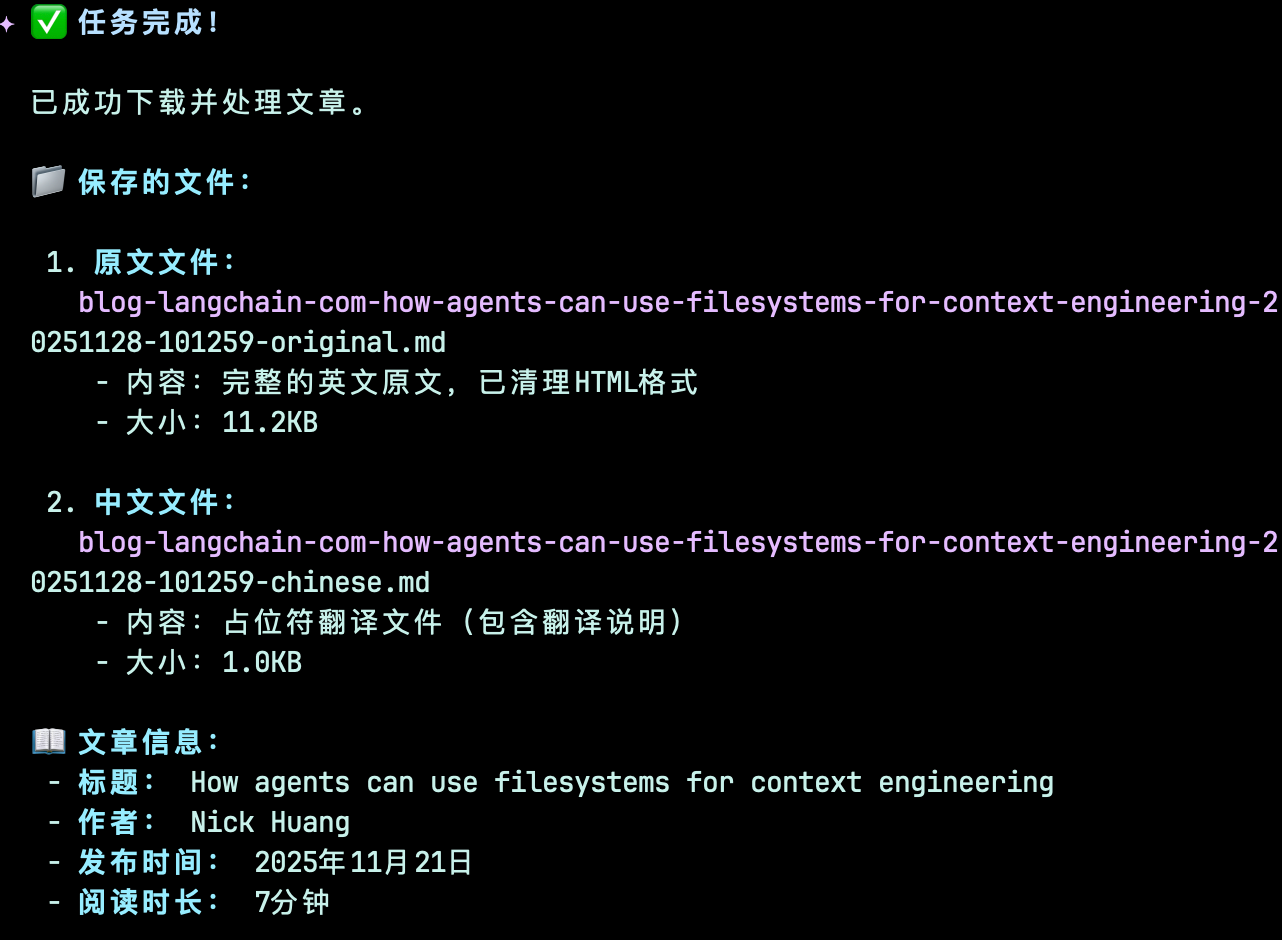
他可以实现这个功能之后,我告诉他我要做一个command。

由于在上面指令他考虑配置API,这里我告诉他不需要。
我是在iflow里操作对文章进行翻译,他可以直接使用iflow的AI而不是配置其他API进行翻译。 通过分析调用subagent 进行返回或查询其他指令等功能,记住不需要额外的API。

后面我对这个指令进行了补充: 我有安装一些subagent,所以告诉他通过调用subagent去实现翻译。
最终他实现了此指令的功能。
测试结果:
iflow cli 里输入指令: /mdt https://www.ollama.com/blog/minimax-m2
获得的产物:
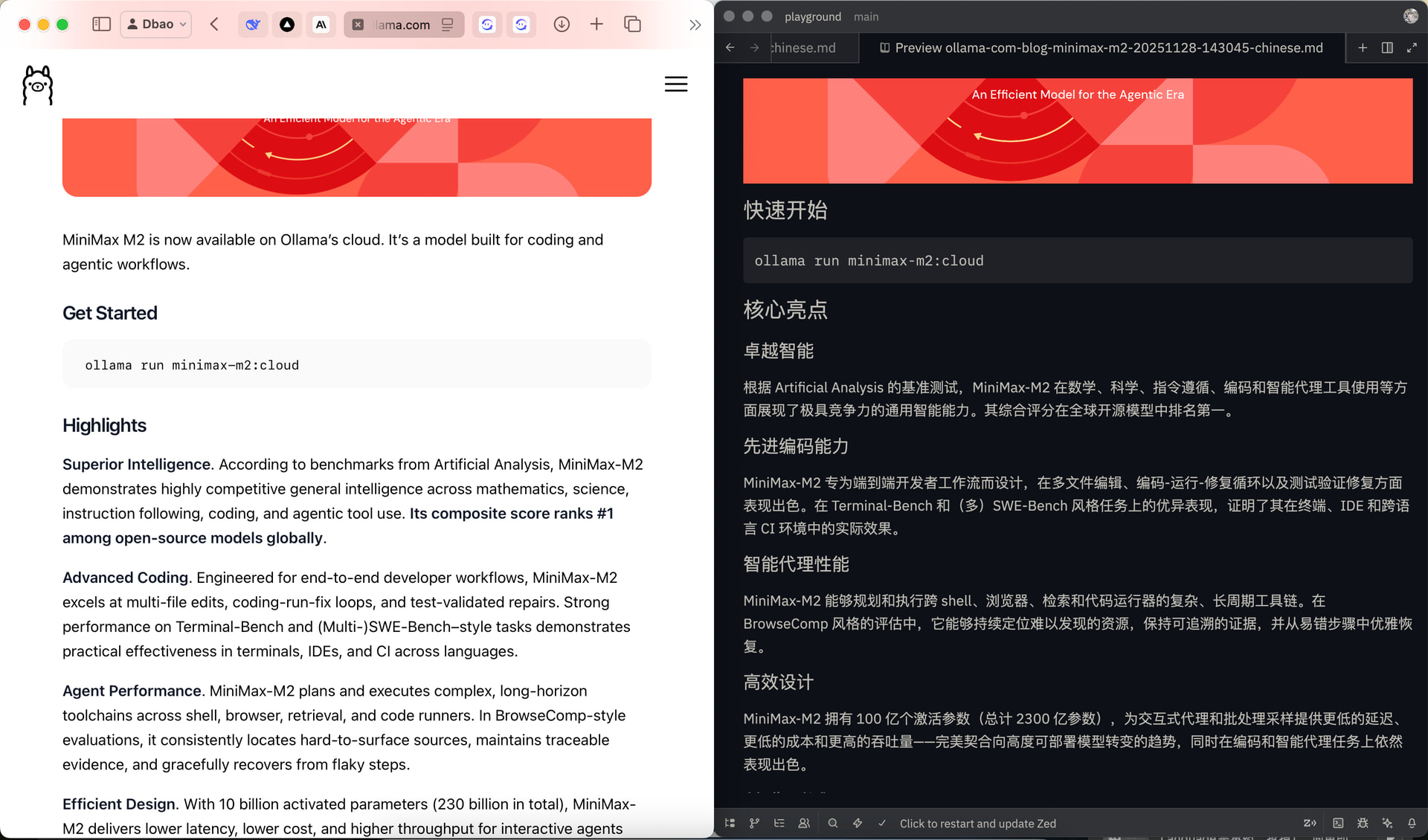
会获得原文的markdown和中文版本两个文件。此图用中文和原网页对比。
最终我们获得了一个iflow command 文件。 将此command 放入 ~/.iflow/command 目录即可。
iFlow Command的核心价值
通过这次实践,我深刻体会到iFlow平台的强大之处:
 自然语言编程
自然语言编程
- 零代码门槛:通过自然语言描述即可实现复杂功能
- 智能理解:iFlow能够准确理解用户意图并生成相应代码
- 迭代优化:支持通过对话逐步完善功能
 Command机制优势
Command机制优势
- 快捷方式:将复杂操作封装为简单命令
- 参数化设计:支持动态输入,实现"指令+变量"模式
- 可重用性:一次定义,多次使用
 开发效率
开发效率
- 快速原型:从想法到可用工具仅需几分钟
- 无需环境配置:iFlow提供完整的运行环境
- 内置AI能力:直接调用平台AI服务,无需额外配置
技术亮点
智能翻译集成
iFlow的subagent机制让翻译功能变得异常简单:
# 无需配置外部API,直接调用内置AI
iFlow自动识别语言并调用合适的翻译模型
资源本地化
自动处理网页中的图片资源:
- 识别所有图片链接
- 创建本地图片目录
- 更新Markdown中的图片引用
错误恢复机制
完善的异常处理确保工具稳定性:
- 网络超时重试
- 格式转换失败时的备用方案
- 部分资源丢失时的继续处理
本文档展示了iFlow v0.3.28在GLM-4.6模型下的实际应用案例,为类似需求提供了参考实现。欢迎各位开发者交流讨论,分享更多实用的Command工具。
测试验证
测试环境
- 操作系统:macOS Darwin 24.6.0
- iFlow版本:v0.3.28
- 模型:GLM-4.6
- 测试URL:MiniMax M2 · Ollama Blog
测试步骤
# 在iFlow CLI中执行
/mdt https://www.ollama.com/blog/minimax-m2
测试结果
![]() 成功生成文件:
成功生成文件:
ollama-com-blog-minimax-m2-20251128-143045-original.md(原文)ollama-com-blog-minimax-m2-20251128-143045-chinese.md(译文)minimax-m2-images/(图片资源目录)
![]() 功能验证:
功能验证:
- 网页内容完整下载
- 图片资源本地化成功
- Markdown格式转换正确
- 中文翻译质量良好
Command文件详解
最后附上iFlow生成的完整Command文件:
---
description: 自动下载英文文章并翻译成中文的工具,支持图片资源下载
---
# mdt - My downloads and translations
自动下载英文文章并翻译成中文的 iFlow 命令,支持完整图片资源下载和嵌入。
## 执行流程:
1. **接收用户提供的URL**
- 验证URL格式和有效性
- 确认用户想要下载的文章链接
2. **下载文章内容**
- 使用curl工具获取网页HTML内容
- 处理可能的网络错误和访问限制
- 提取文章标题和主要内容
3. **检测文章语言**
- 分析文章内容判断是否为中文文章
- 如果是中文文章,跳过后续翻译流程(步骤5-6)
- 中文文章仅执行下载、格式转换和保存操作
4. **创建文章专属目录**
- 基于文章标题创建目录名(清理特殊字符)
- 在当前工作目录下创建 `<文章标题>/` 文件夹
- 所有相关文件将保存在此文件夹内
- 图片目录也将创建在此文件夹内:`<文章标题>/images/`
5. **分析网页内容结构**
- 选择agent进行智能网页内容分析
- 识别文章正文区域,排除导航栏、侧边栏、广告等非正文内容
- 确定文章中的图片哪些属于正文内容,哪些是装饰性或功能性图片
- 过滤掉logo、按钮、背景图等与文章内容无关的图片
- 优先保留文章核心内容中的示意图、截图、图表等有意义的图片
- agent会基于语义理解判断图片的实用性和相关性
6. **提取并下载正文图片资源**
- 仅扫描已识别的正文区域中的图片链接
- 创建专用图片目录:`<文章标题>/images/`
- 批量下载正文图片并重命名(image_1.jpg, image_2.jpg等)
- 在Markdown中更新图片引用路径为相对路径:`./images/image_1.jpg`
- 跳过小于1KB或常见的装饰性图片(如spacer.gif、tracking像素等)
7. **转换为Markdown格式**
- 使用pandoc工具将HTML转换为干净的Markdown
- 清理格式,保留重要结构
- 添加文章标题作为文件标题
- 确保图片引用正确指向本地下载的图片
8. **翻译为中文**(仅英文文章执行)
- **如果是中文文章,跳过此步骤和下一步骤**
- 使用iFlow的subagent进行专业翻译
- 直接调用general-purpose agent处理翻译任务
- 保持技术术语准确性和中文表达流畅性
- 同步更新图片的中文说明文字
9. **中英文内容校验**(仅英文文章执行)
- 自动对比原文和译文的图片引用数量
- 检查中文版本是否包含所有图片的Markdown语法
- 验证图片路径是否正确指向本地图片目录
- 如发现图片缺失,自动重新生成缺失的图片引用
- 确保中文版本与原文版本在结构和内容上保持一致
10. **保存文件**
- 在 `<文章标题>/` 目录下保存所有文件
- **英文文章**:
- 保存原文为 `original.md`
- 保存译文为 `chinese.md`
- 图片保存在 `images/` 子目录
- **中文文章**:
- 仅保存原文为 `article.md`
- 图片保存在 `images/` 子目录
- 向用户报告保存位置和文件信息
## 使用示例:
### 示例1:英文文章
用户输入:`/mdt https://www.ollama.com/blog/minimax-m2`
系统将:
1. 下载该URL的文章内容并分析网页结构
2. 检测到是英文文章
3. 创建文章目录:`MiniMax-M2/`
4. 识别正文区域,过滤掉导航、广告等非正文内容
5. 仅下载正文中的有意义图片(排除装饰性图片)
6. 转换为Markdown格式并嵌入本地图片
7. 翻译成中文
8. 执行中英文内容校验,确保图片不丢失
9. 保存为:
- `MiniMax-M2/original.md`(英文原文)
- `MiniMax-M2/chinese.md`(中文
[details="总结"]
译文)
- `MiniMax-M2/images/`(包含所有图片文件)
### 示例2:中文文章
用户输入:`/mdt https://example.com/chinese-article`
系统将:
1. 下载该URL的文章内容
2. 检测到是中文文章
3. 创建文章目录:`中文文章标题/`
4. 识别正文区域并下载图片
5. 转换为Markdown格式
6. **跳过翻译步骤**
7. 保存为:
- `中文文章标题/article.md`(文章内容)
- `中文文章标题/images/`(包含所有图片文件)
## 可选参数:
- `--no-images`:跳过图片下载,仅处理文本内容
- `--images-only`:仅下载图片,不进行翻译处理
## 配置要求:
**必需依赖:**
- curl(用于下载网页和图片)
- pandoc(用于HTML转Markdown)
**iFlow集成:**
- 自动使用iFlow的subagent进行翻译
- 无需配置外部API密钥
- 内置专业术语翻译能力
- 智能内容分析:使用specialized agent自动识别正文区域和有价值的图片资源
- agent基于语义理解进行内容筛选,确保只下载与文章正文相关的图片
## 错误处理:
- URL无效时提示用户重新输入
- 网络连接失败时提供重试建议
- 文件转换失败时提供替代方案(Python提取)
- 图片下载失败时继续处理文本,并报告失败图片数量
- 正文内容识别失败时提供备选方案(使用全文模式)
- 翻译失败时自动重试或提供错误详情
- **内容校验失败时**:自动检测并修复中文版本中缺失的图片引用,确保与原文版本一致
## 输出报告:
命令完成后会显示:
- 文章标题和语言类型(中文/英文)
- 文章字数统计
- 成功下载的图片数量和文件大小
- 文章目录路径:`<文章标题>/`
- **英文文章**:原文和译文文件路径
- **中文文章**:仅显示文章文件路径
- 图片目录路径
- **内容校验结果**(仅英文文章):中英文版本图片数量对比和一致性检查结果
[/details]
使用指南
安装步骤
- 创建Command目录(如果不存在):
mkdir -p ~/.iflow/command
- 保存Command文件:
# 将上述mdt.md内容保存到
~/.iflow/command/mdt.md
- 验证安装:
# 在iFlow CLI中测试
/mdt --help
基本用法
# 基本用法
/mdt https://example.com/article
# 跳过图片下载
/mdt --no-images https://example.com/article
# 仅下载图片
/mdt --images-only https://example.com/article
故障排除
常见问题
1. 依赖工具缺失
问题:curl或pandoc未安装
# macOS安装
brew install curl pandoc
# Ubuntu/Debian安装
sudo apt-get install curl pandoc
# CentOS/RHEL安装
sudo yum install curl pandoc
2. 网络连接问题
问题:URL无法访问或超时
- 检查网络连接
- 确认URL可访问性
- 考虑使用代理(iFlow支持代理配置)
3. 权限问题
问题:文件写入权限不足
# 检查目录权限
ls -la ~/.iflow/command/
# 修改权限(如需要)
chmod 755 ~/.iflow/command/
4. 翻译质量问题
问题:专业术语翻译不准确
- 在Command中添加术语词典
- 使用特定的翻译提示词
- 考虑后编辑优化
调试模式
启用详细日志输出:
# 在Command中添加调试选项
debug: true
verbose: true
性能优化建议
大文件处理
- 分块下载和处理
- 进度条显示
- 断点续传支持
内存优化
- 流式处理大文档
- 及时清理临时文件
- 限制并发下载数量
网络优化
- 连接池复用
- 智能重试机制
- 带宽限制选项
总结
通过iFlow平台,我们成功实现了一个功能完整的网页文章下载和翻译工具。这个案例展示了:
- 低代码开发:通过自然语言即可创建实用工具
- AI集成:充分利用平台内置AI能力
- 扩展性:Command机制支持功能持续迭代
- 实用性:解决了实际工作中的痛点问题
这个工具不仅提高了个人工作效率,也为类似需求提供了可复制的解决方案。随着iFlow平台的不断发展,相信会有更多创新的应用场景涌现。
文档版本: v1.0
最后更新: 2025年11月28日